

In the field of artificial intelligence, closed-source systems such as ChatGPT and Claude hold an advantage in understanding complex images like financial forecasts and medical charts, but their secretive training methods and data sources have limited the progress of open-source models. Now, researchers from the University of Pennsylvania's School of Engineering and the Allen Institute for AI (Ai2) have developed a new method called CoSyn, which uses open-source AI models to generate scientific figures, charts, and tables, providing other AI systems with data to learn how to “see” and understand complex visual information.
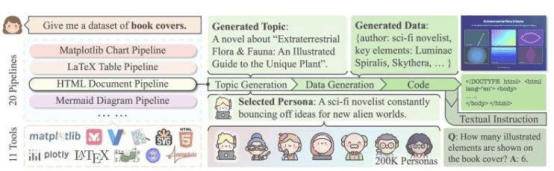
CoSyn, short for Code-guided Synthesis, leverages the coding abilities of open-source AI models to incorporate textual information into images and generate related questions and answers, building a dataset rich in instructional value. In a paper presented at the ACL 2025 conference, the research team noted that models trained with CoSyn perform comparably or even better than proprietary models on multiple benchmarks. Co-first author Yue Yang vividly explained: “It's like asking a student who excels at writing to teach others how to draw—simply by describing what the picture should look like.”
The CoSyn-generated dataset, CoSyn-400K, contains over 400,000 synthetic images and 2.7 million instruction pairs, covering scientific charts, chemical structures, and multiple other domains. In the task of recognizing nutritional labels, a model trained with only 7,000 synthetic labels outperformed models trained on millions of real images, demonstrating CoSyn's remarkable data efficiency. Professor Mark Yatskar stated: “Synthetic data can help models better adapt to the real world, for example, assisting people with low vision in reading nutritional labels.” To ensure data diversity and avoid repetition, the team developed the DataDreamer software library and introduced the “persona” concept to guide AI in generating rich and varied training data.
By building CoSyn entirely with open-source tools, the research team aims to break the monopoly of proprietary models and provide the open-source AI community with a powerful method for visual-language training. Professor Chris Callison-Burch emphasized: “This opens the door for AI systems capable of reasoning over scientific literature, benefiting a wide range of people.” The team has now released the CoSyn code and dataset publicly, inviting the global research community to build upon it. Dr. Yang Zhiyuan concluded: “We hope AI can act in the real world, and CoSyn is a key step in teaching it how to do so.”