

When we observe the world around us, the brain not only recognizes specific objects but also understands the broader meaning of scenes. However, for a long time, scientists have lacked effective means to quantify this complex understanding. A new study published today in the journal Nature Machine Intelligence, led by Ian Charest, Associate Professor of Psychology at the University of Montreal, in collaboration with colleagues from the University of Minnesota, Osnabrück University in Germany, and Freie Universität Berlin, has successfully addressed this challenge using large language models (LLMs).
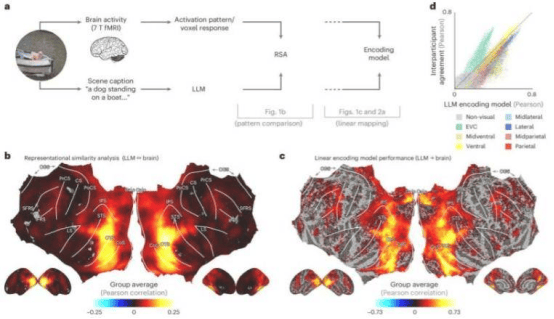
"We fed natural scene descriptions into LLMs to create language-based fingerprints that represent the meaning of scenes," Charest explained. "These fingerprints closely matched the patterns of brain activity recorded in fMRI scans when people viewed the same scenes — whether it was children playing or a city skyline." He further explained that, with the help of LLMs, researchers can decode the visual scenes people perceive with a single sentence and even predict the brain's response to scenes involving food, places, or faces. The research team went further by training artificial neural networks to receive images and predict LLM fingerprints, finding that their ability to match brain responses surpassed many existing state-of-the-art AI vision models.
Although these models were trained on relatively less data, the results remain remarkable. Professor Tim Kietzmann from Osnabrück University and his team provided support for the artificial neural network architecture, and Professor Adrien Doerig from Freie Universität Berlin is the first author of the study. "Our findings suggest that the way the human brain processes complex visual scenes may be strikingly similar to the way modern language models understand text," Charest said. This research opens new paths for decoding thoughts, optimizing brain-computer interfaces, and building smarter AI systems that can more closely mimic the way humans "see" the world. In the future, more advanced visual computing models are expected to help autonomous vehicles make wiser decisions and may even lead to the development of visual prostheses for people with visual impairments.