en.Wedoany.com Reported - Google has introduced an AI memory compression technology called TurboQuant, designed to optimize memory usage for large language models and vector search engines. This technology can reduce memory footprint by approximately 6 times while increasing attention computation speed by up to 8 times, all without loss of model accuracy. TurboQuant is expected to be officially showcased later this month at the ICLR 2026 conference in Brazil.
TurboQuant combines two complementary techniques: PolarQuant and the QJL algorithm. PolarQuant simplifies the geometric structure of data vectors through random rotation, achieving high-quality compression; QJL utilizes the remaining compression capacity of approximately 1 bit to eliminate bias, ensuring accurate attention scores. Google stated in a blog post: "The algorithm essentially creates a high-speed shorthand without memory overhead."
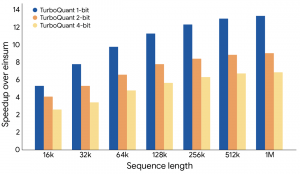
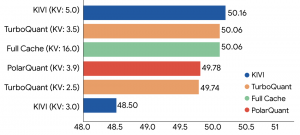
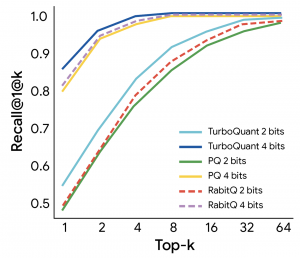
In multiple benchmark tests, such as ZeroSCROLLS and Needle in a Haystack, TurboQuant significantly reduced memory usage while maintaining high accuracy. Tests showed it can compress cache precision from 16 bits to approximately 3 bits, achieve an 8x speedup on H100 GPUs, and improve recall rates for vector search.
TurboQuant not only optimizes compression efficiency but also alleviates memory bandwidth limitations, providing a new path for scaling AI systems. As model sizes grow, this technology that reduces memory requirements without impacting accuracy may become a key factor in advancing AI development.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com