
en.Wedoany.com Reported - French artificial intelligence company Mistral AI on Tuesday released its fourth-generation optical character recognition model, OCR 4. The core capability of this model extends beyond text extraction, returning a structured representation of documents that includes bounding boxes, block type classifications, and per-word confidence scores. The product is positioned for the self-hosted enterprise deployment market in regulated industries, where companies cannot entrust sensitive documents to cloud service providers under U.S. jurisdiction.

OCR 4 supports 170 languages across 10 language families and can process PDF, DOC, PPT, and OpenDocument formats. Mistral stated that while previous generations primarily converted pages into clean text and tables, OCR 4 directly returns a structured representation of the document. The model is available via the Mistral API, Document AI in Mistral Studio, Amazon SageMaker, and Microsoft Foundry, with Snowflake Parse Document support coming soon. Pricing starts at $4 per 1,000 pages, with a batch API discount rate of $2 per 1,000 pages.
The engineering core of OCR 4 is outputting a layered document representation rather than a flat text stream. Each text block comes with bounding box positioning, type classification (e.g., title, table, formula, signature), and confidence scores at both page and word levels. Mistral noted that bounding boxes are the most frequently requested feature by customers, enabling downstream systems to trace extracted information back to specific page locations. Block classification allows title paragraphs to be used for hierarchical segmentation in semantic search, routes table blocks to structured data pipelines, and enables signature blocks to trigger editing workflows in compliance systems. Confidence scores allow organizations to programmatically route low-confidence areas for human review while automatically approving high-confidence extractions.
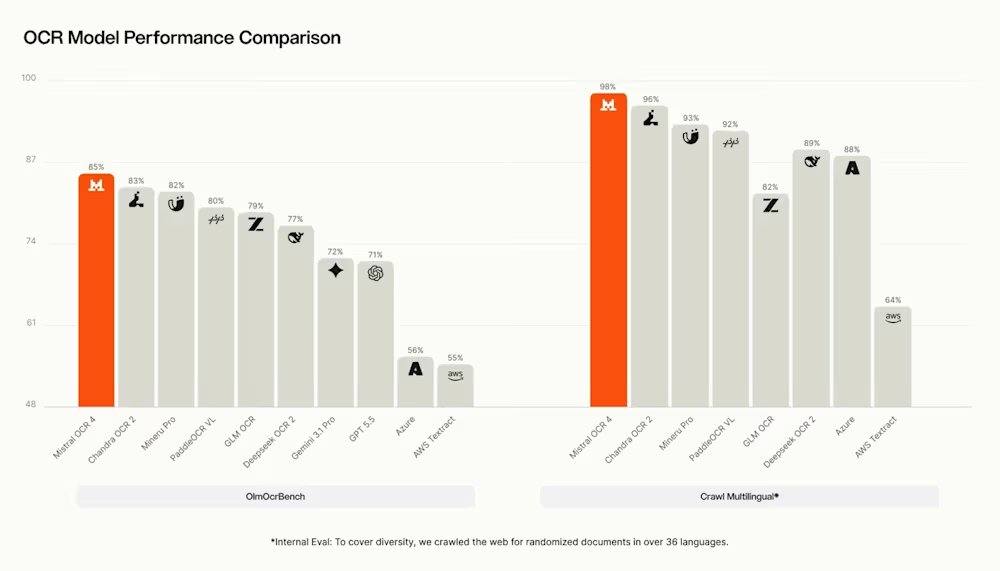
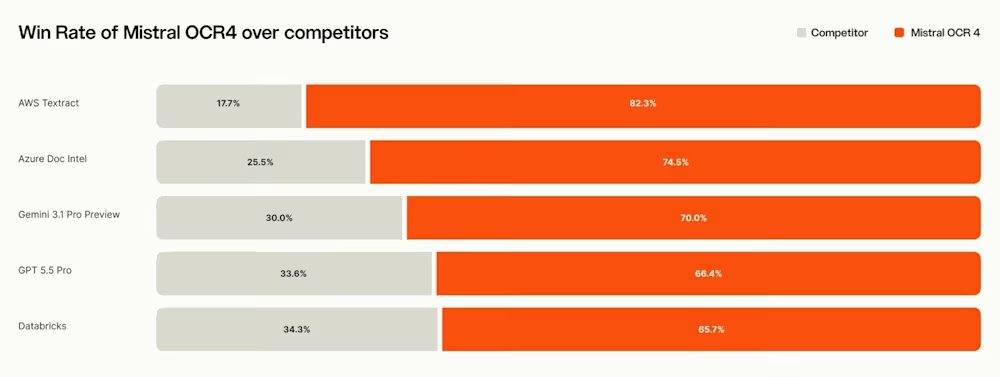
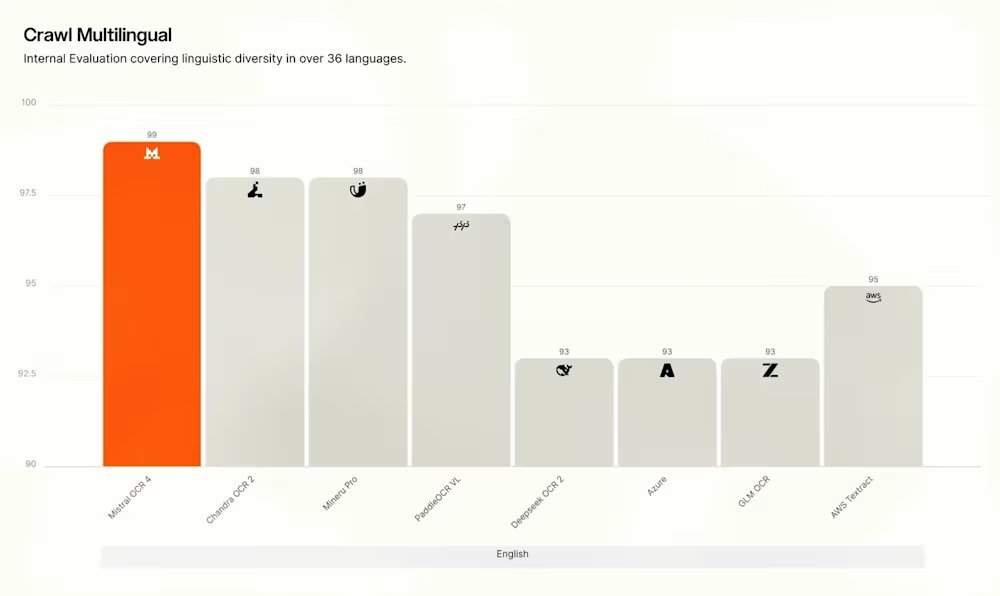
In independent evaluations, Mistral reported that a human assessment by independent annotators on over 600 real-world documents in more than 12 languages showed OCR 4 achieving an average win rate of 72% in direct comparisons with major competitors. The model scored 85.20 on OlmOCRBench and 93.07 on OmniDocBench. However, Mistral also proactively audited and publicly disclosed artifacts in the scores, including errors in reference annotations, LaTeX symbol matching issues, column reading order assumptions, and considers the total scores to be directional rather than definitive. Notably, on the public OlmOCRBench leaderboard, OCR 4 currently ranks third, trailing some open-weight models such as Chandra OCR 2. PaddleOCR-VL-1.6 claims a comprehensive score of 96.33 on OmniDocBench.
Early enterprise feedback provides specific data points. Aidan Donohue, an AI engineer at financial AI company Rogo, stated that on a chart-intensive financial question-answering dataset, OCR 4 achieved "comparable accuracy to leading agentic document parsers at roughly 8x lower cost and 17x lower latency." Ivan Mihailov, an AI engineer at intellectual property management company Anaqua, noted that OCR 4's "speed per page is approximately 4x faster than existing vendors."
The geopolitical backdrop of this release is the June 12 incident where Anthropic disabled its latest models, Fable 5 and Mythos 5, due to U.S. export controls, causing service disruptions for enterprise customers in finance, healthcare, and critical infrastructure sectors. This event validated Mistral CEO Arthur Mensch's warnings about the risks of European dependence on U.S. AI companies. Mensch stated that U.S. companies "hold the keys to their models" and recently emphasized that "Europe has fallen behind in building infrastructure, so we are investing to close this gap." OCR 4's single-container self-hosted deployment model ensures documents never leave customer infrastructure, operating entirely under EU jurisdiction.
The day before Mistral's release, Baidu launched a 3-billion-parameter model called Unlimited-OCR, with open weights under the MIT license. This model uses a technique called Reference Sliding Window Attention (R-SWA), enabling it to parse entire PDFs and multi-page scans in a single forward pass without chunking or stitching. Analysts view these two releases as representing a divergence in the document AI landscape in June 2026: open-weight self-hosted long-range parsing versus commercialized structured hosted extraction. For research teams on a single GPU, Unlimited-OCR may be more suitable, while OCR 4 targets the service level agreements, data processing agreements, and compliance audits involved in enterprise IT procurement processes.
From an industry perspective, OCR 4 is Mistral's entry point into enterprise AI budgets. The model directly supports Mistral's Search Toolkit, an open-source composable search framework. Architecturally, OCR 4 serves as the extraction layer for retrieval-augmented generation and enterprise search pipelines. Bloomberg recently reported that Mistral is in early-stage negotiations to raise approximately 3 billion euros at a valuation of around 20 billion euros. The company aims for 1 billion euros in revenue by 2026. Mistral's CEO recently also pushed back against the Pope's call for AI to be "disarmed," arguing that Europe cannot fall behind U.S. tech giants and needs to possess its own AI capabilities.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










