
en.Wedoany.com Reported - Alibaba's Qwen team has released Qwen-AgentWorld, featuring two models designed not to execute actions in agent environments, but to predict the outcomes returned by these environments, covering seven domains: MCP, search, terminal, software engineering, Android, Web, and operating systems.
This release continues Alibaba's recent investment in autonomous agents, following the May launch of Qwen3.7-Max, which is built around 35 hours of autonomous execution capability. The team noted that the core bottleneck in large-scale agent training lies in the limitations of real-world environments: search engines cannot inject controlled conditions, real-time terminals do not allow on-demand simulation of edge cases like low disk space, and agents struggle to be systematically exposed to rare scenarios.
The research team trained agents in generated simulators and found that their performance improved beyond that of agents trained solely in real environments. In another test, using world model training as a warm-up step before agent fine-tuning improved performance across all seven benchmarks, three of which were never seen during training. The accompanying paper states that world modeling is a key component in achieving general-purpose agents.
Unlike traditional agent models that optimize action selection, Qwen-AgentWorld is trained to answer the inverse question: given the action just executed by the agent, what will the environment display next? The paper terms this approach a "language world model," where the model learns to predict the next environmental state across all seven domains under a single training objective. Previous related research has been narrower in scope; for example, Qwen's February release, WebWorld, only covered web environments, while Snowflake's Agent World Model, released the same month, generated code-driven SQL support environments rather than training models to predict states. Qwen-AgentWorld is the first model to span seven domains within a single model and incorporate environmental modeling from the earliest pre-training stage.
The training process used over ten million environmental interaction trajectories from real agent runs, divided into three stages: the first stage teaches the model how environments operate, including file systems, terminal states, browser DOM changes, and API responses; the second stage trains the model to reason about subsequent states before making predictions; and the third stage tightens predictions through reinforcement learning, using rule-based checks and open-ended quality scoring. Both models adopt a mixture-of-experts design, activating only a small fraction of parameters per token. The 35B model activates 3B, and the 397B model activates 17B, both supporting a 256K context window. For GUI domains (Android, Web, and operating systems), the models work from text accessibility trees and UI view hierarchies rather than screenshots. The 35B model weights and AgentWorldBench are available under the Apache 2.0 license; the 397B weights have not yet been publicly released.
Benchmark scores indicate the accuracy with which the models predict environmental returns, but the training results reveal the practical value of this predictive capability for building agent teams, and these numbers are more significant. According to the researchers, agents trained in controlled simulations outperformed those trained in real environments. Injecting targeted perturbations improved MCPMark from 24.6 to 33.8. In search tasks, agents trained in entirely fictional worlds transferred to real search tasks, improving WideSearch F1 Item on the open-source 35B model from 34.02 to 50.31. Warm-up tests showed that world model pre-training improved BFCL v4 from 62.29 to 71.25 and Claw-Eval from 53.60 to 64.88, without any agent-specific fine-tuning.
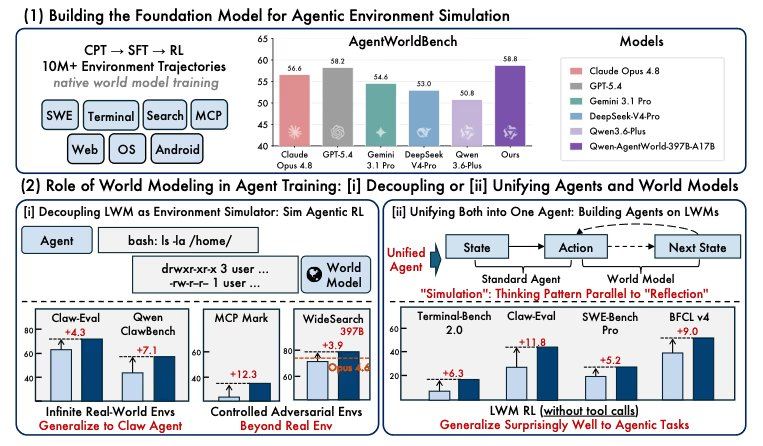
The paper's release sparked discussion among AI researchers. Some argued that Qwen inverted the core problem by training the model to predict the environment itself, with this predictive knowledge subsequently transferring to agent tasks, even without agent-specific fine-tuning. Other researchers noted that AgentWorldBench is a benchmark built and released by Alibaba in the same paper, and that their model won by a margin of 0.46, potentially raising questions about the independence of evaluation standards. A traditional issue with simulated RL methods is that agents tend to overfit to simulator characteristics; if the world model is too clean, the agent learns the model rather than the task. The paper's held-out partitions and data results partially address these concerns, with search results from fictional worlds indicating that agents trained in these environments can transfer to real search tasks.
For teams building and scaling agent pipelines, this work offers a third option: controlled simulations that inject edge cases absent from production environments. Synthetic environments represent a legitimate training layer, complementing real-world RL rather than serving as a shortcut to bypass it. Environmental grounding before agent training takes effect earlier in the development process than most current practices, improving performance across multiple benchmarks without requiring agent-specific training. What the model learns before training is far more important than most pipelines account for.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










