
en.Wedoany.com Reported - A nine-person research team from Sina Weibo has launched VibeThinker-3B, a compact language model with 3 billion parameters, which matches or surpasses larger systems from institutions such as Google DeepMind, OpenAI, AI safety company Anthropic, and DeepSeek across multiple reasoning benchmarks.
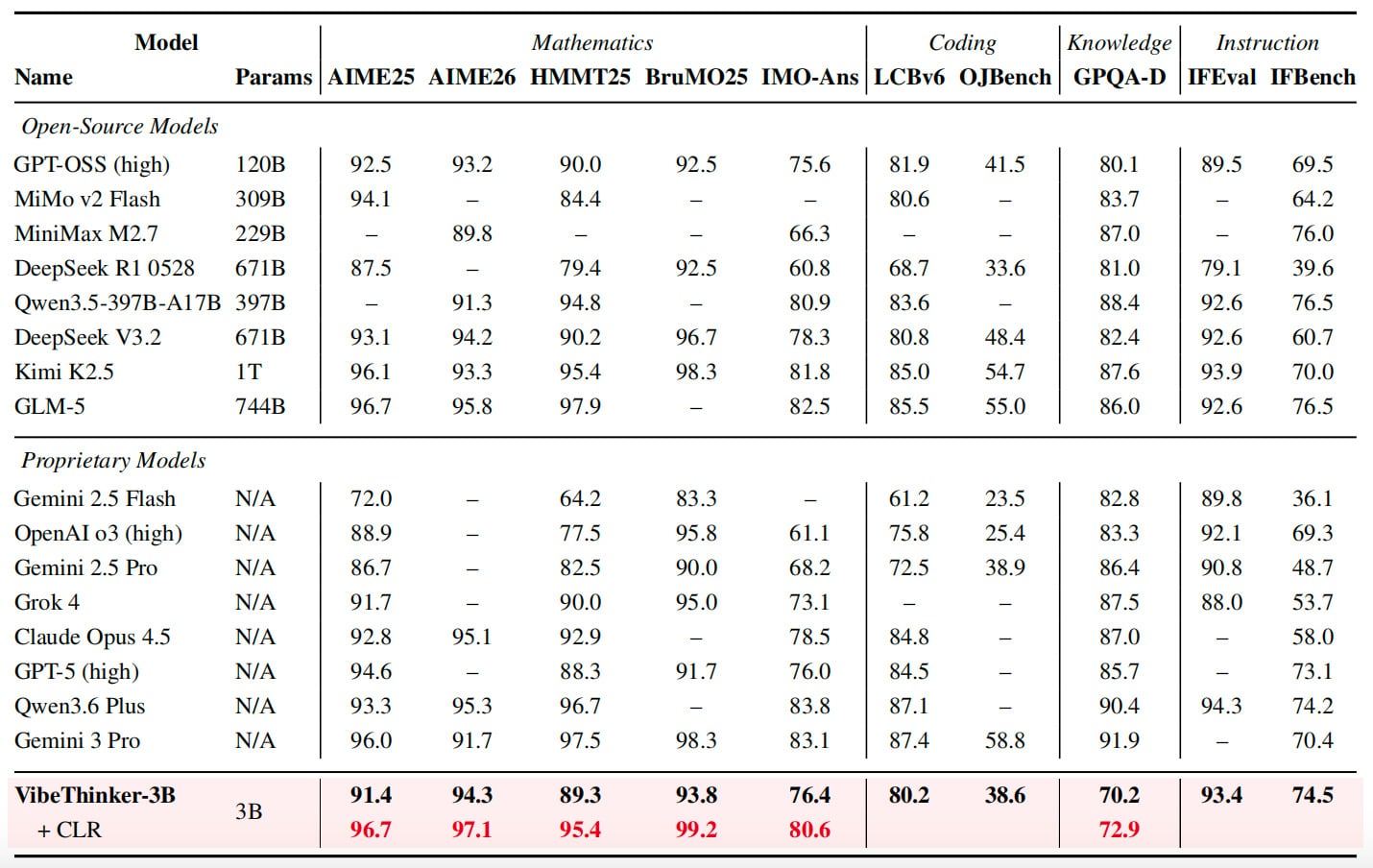
The model scored 94.3 on AIME 2026, comparable to the performance range of DeepSeek V3.2 with 671 billion parameters, and outperformed Gemini 3 Pro's score of 91.7. Through a test-time scaling method called "Claim-Level Reliability Assessment," VibeThinker-3B's score on AIME 2026 further improved to 97.1.
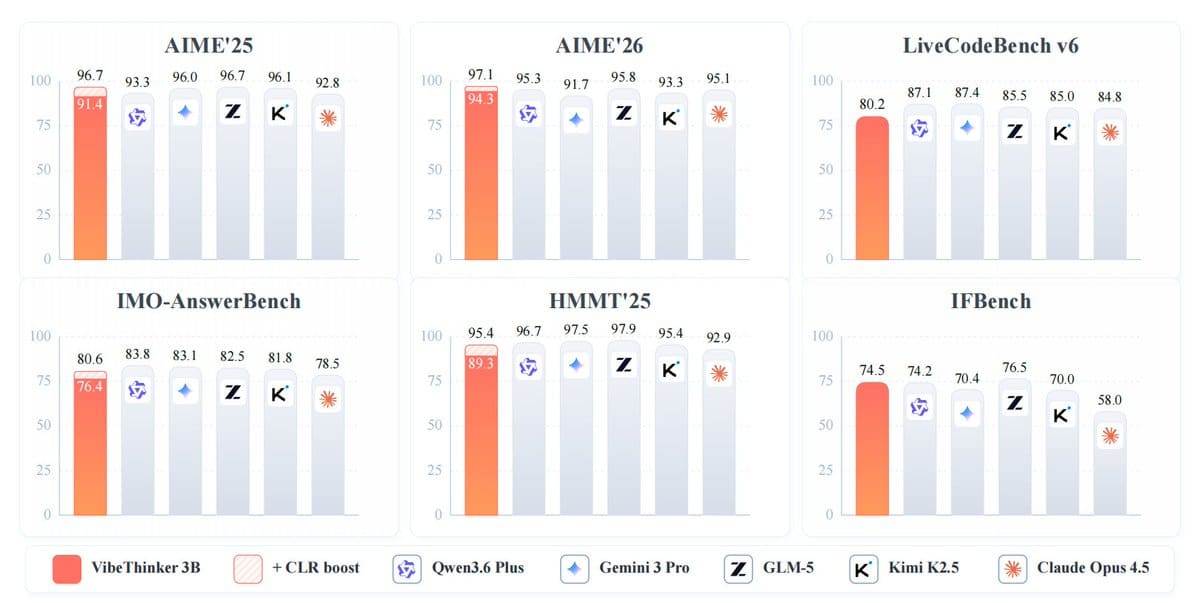
On other benchmarks, VibeThinker-3B scored 91.4 on AIME 2025, 89.3 on HMMT 2025, 93.8 on BruMO 2025, and 76.4 on IMO-AnswerBench. In coding ability, the model achieved a Pass@1 score of 80.2 on LiveCodeBench v6 and a 96.1% submission acceptance rate on unseen LeetCode weekly and biweekly contests held from late April to late May 2026. On the instruction-following test IFEval, it scored 93.4.
The model passed 123 out of 128 first-time submitted LeetCode problems, surpassing GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5, and Claude Opus 4.6 under the same evaluation conditions.
VibeThinker-3B has approximately 1/224th the parameters of DeepSeek V3.2. In comparison, GLM-5 has 744 billion parameters, while Kimi K2.5 exceeds one trillion. The model is compact enough to run on consumer-grade laptops. The research team believes that verifiable reasoning tasks, such as mathematics and coding, can be compressed into smaller models more effectively than broad factual knowledge, a concept they term the "Parameter Compression Coverage Hypothesis."
The model does not excel in all areas. On the GPQA-Diamond test, it scored 70.2, compared to Gemini 3 Pro's 91.9 and Claude Opus 4.5's 87.0. The research team states that this supports their argument that compact models can perform strongly on verifiable reasoning tasks but cannot replace larger models that provide broader knowledge coverage.
VibeThinker-3B is based on Alibaba's Qwen2.5-Coder-3B and was improved through a four-stage post-training pipeline. The first stage uses supervised fine-tuning on data for mathematics, coding, STEM reasoning, dialogue, and instruction-following, then shifts to harder, longer reasoning problems. Training samples with reasoning traces shorter than 5000 tokens are removed, as are problems that the earlier version VibeThinker-1.5B could solve over 75% of the time. The second stage employs reinforcement learning on mathematics, coding, and STEM tasks using MaxEnt-Guided Policy Optimization. Researchers used a single 64,000-token window instead of progressively expanding the context window, as progressive expansion reduced performance at the 3B scale. A separate "Long2Short Math RL" stage rewards shorter correct answers to reduce unnecessary verbosity. The third stage distills successful reasoning traces from reinforcement learning checkpoints back into a unified model. The final stage applies reinforcement learning to instruction-following tasks using rule-based checks and reward models.
The test results have attracted attention but also raised concerns about potential over-optimization for benchmarks. Some users report that the model performs poorly on real-world coding problems, including difficulties with common development tools. Others question why the model was not tested on broader software engineering benchmarks. Researchers state that the training data underwent rigorous benchmark decontamination, including filtering overlapping text. Recent LeetCode contests provide stronger data leakage protection as they occurred after any possible training cutoff date. However, user reports still indicate a gap between benchmark scores and real-world performance.
The model is released under the MIT license, with weights available via Hugging Face and ModelScope. Within the first day of release, developers had already generated GGUF quantized versions and derivative models.
Sina Weibo is better known for its social media platform than for cutting-edge AI research. VibeThinker-3B is the company's second major open-source AI release in seven months. VibeThinker-1.5B, released in November 2025, reportedly outperformed the original DeepSeek R1 on multiple math benchmarks. The team states that its post-training cost was $7,800, compared to an estimated $294,000 for DeepSeek R1.
Researchers do not claim that VibeThinker-3B can replace large general-purpose models. They suggest that in hybrid AI systems, small models could handle reasoning tasks while larger systems provide factual knowledge. This approach could reduce the cost of deploying advanced reasoning and offer strong math and coding capabilities on hardware-limited devices. The key question is whether the model's benchmark performance translates into reliable real-world applications.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










