
en.Wedoany.com Reported - Researchers at the Shanghai Artificial Intelligence Laboratory have proposed a new paradigm called "Self-Harness," which allows large language model (LLM)-based agents to systematically improve their own operational rules without relying on human engineers or stronger external models.
The performance of LLM-based agents depends not only on the underlying model but also on their framework, which includes system prompts, tools, memory, validation rules, runtime policies, orchestration logic, and failure recovery procedures. Common agent failures often stem from the framework rather than the model itself. For example, an agent might report success without checking the model's response, or repeatedly retry failed operations. SWE-agent, Claude Code, Codex, and OpenHands are popular examples of such frameworks.
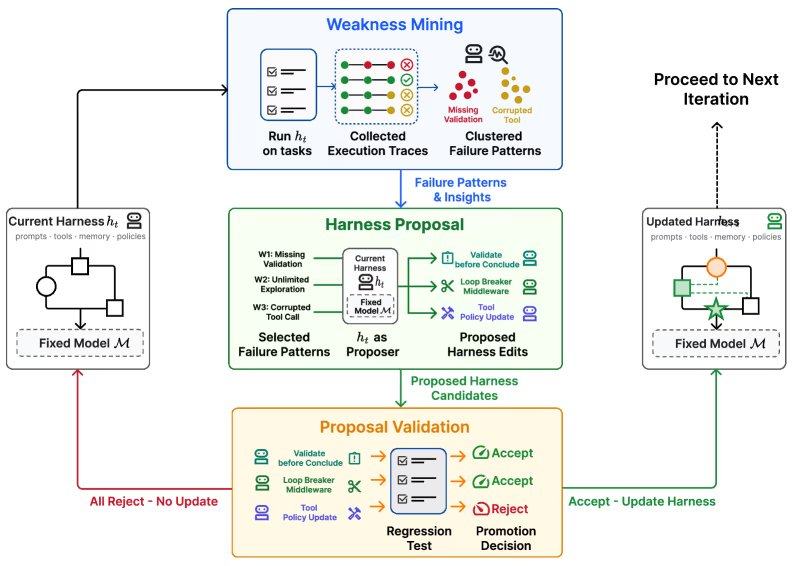
Hangfan Zhang, the first author of the Self-Harness paper, stated that the real bottleneck in manual framework engineering lies in relying on ad-hoc debugging rather than systematic feedback loops. Many edits are based on intuition or a small number of failure cases, making it difficult to keep pace with the rapidly evolving LLMs. The Self-Harness paradigm enables LLM-based agents to achieve self-evolution through a three-stage iterative cycle.
The cycle begins with a weakness mining stage: the agent runs tasks to generate execution trajectories, classifies failed trajectories, and detects model-specific failure patterns. Next is the framework proposal stage: the agent uses a "proposer" role to generate a diverse and minimal set of framework modifications, each targeting a specific failure mechanism. Finally, there is the proposal validation stage: the system evaluates candidate modifications through regression testing, and an edit is only adopted if it does not cause performance degradation on retained tasks. If multiple candidates pass the tests, they are merged into the next version of the framework.
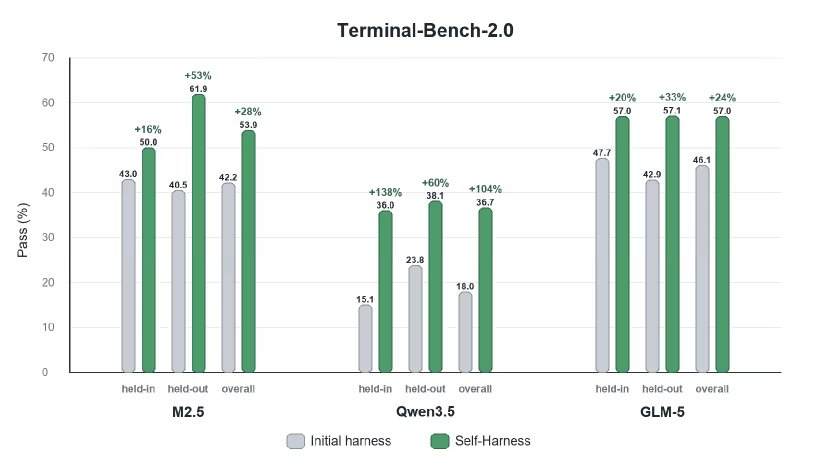
The researchers evaluated Self-Harness on the Terminal-Bench-2.0 benchmark, which tests tool-based execution including artifact management, command usage, validation behavior, and recovery from execution errors. They applied Self-Harness to MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5. Quantitative results showed that agents improved performance through automated framework edits, with relative improvements ranging from 33% to 60% across different models on retained tasks.
Experiments showed that Self-Harness introduced targeted changes reflecting each model's recurring issues during execution. For example, MiniMax M2.5 would endlessly explore dataset configurations under the baseline framework until timeout; the system fixed this by writing a "loop break" rule (stopping and redirecting after 50 tool calls) and adding a requirement to create an initial version early. Qwen-3.5 would repeat the same command after encountering a file overwrite error; the system introduced strict retry discipline (prohibiting exact command repetition) and a mechanism to immediately recreate lost artifacts after file errors. GLM-5 struggled to maintain environment changes across different commands; its self-generated framework introduced rules such as PATH variable persistence, limiting external computations, and fixing any failed sanity checks before the end of execution.
Zhang noted that automated framework engineering requires computational overhead for repeated generation, parallel evaluation, and regression testing. The system also relies on the accuracy of the evaluation pipeline, relying on strict, deterministic validators in experiments. He believes the best deployment targets are areas where failures are measurable and trial-and-error is relatively safe, such as coding, internal workflow automation, and DevOps data pipelines. In contrast, fields like medical decision-making, safety-critical infrastructure, or legal decisions, where evaluation is subjective and costly, should avoid full automation. As foundation model capabilities increase, frameworks will expand outward, connecting to richer external environments. The role of engineers will shift from manually patching individual prompts or tool calls to designing feedback systems that enable agent improvement.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










