en.Wedoany.com Reported - Researchers at Alibaba have developed a framework called SkillWeaver to address the challenge of routing tools for AI agents in multi-step tasks. This framework reduces token consumption by over 99% through a combined skill routing method.
As enterprise AI systems scale, agents need to handle a large number of tools and skills. Existing single-skill selection methods struggle to handle business requests that require multi-step execution, such as "download a dataset, transform the data, and create a visualization report." The research team defines this problem as "composite skill routing," which requires the agent to simultaneously determine how to decompose the task, map sub-tasks to skills, and combine them into an executable plan.
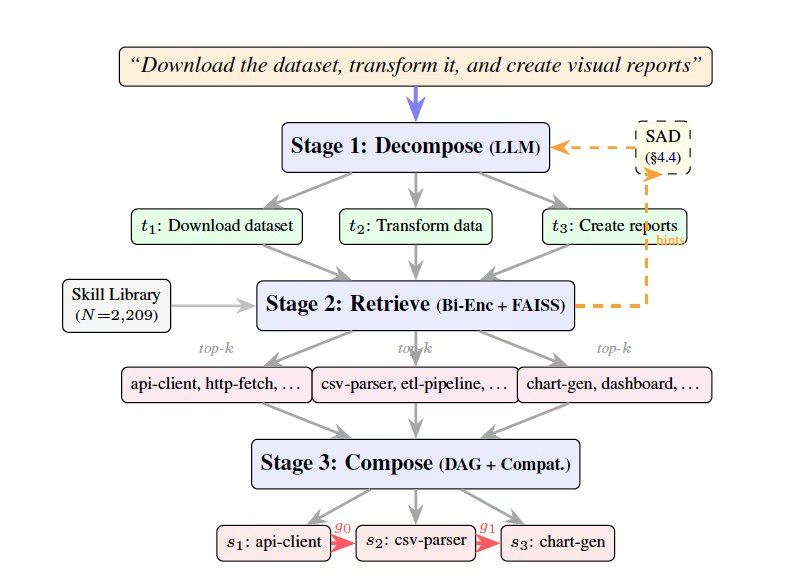
SkillWeaver achieves this process through three stages: decomposition, retrieval, and composition. In the decomposition stage, a large language model breaks down the user query into a series of sub-tasks. The retrieval stage uses an embedding model to extract a shortlist of candidate tools from the skill library for each sub-task. The composition stage evaluates the compatibility of candidate tools and creates an executable plan in the form of a directed acyclic graph. The research team also introduced Iterative Skill-Aware Decomposition (SAD) technology, which uses a feedback loop to allow the large language model to rewrite the decomposition based on preliminary retrieved skill information, aligning granularity with the tool library.
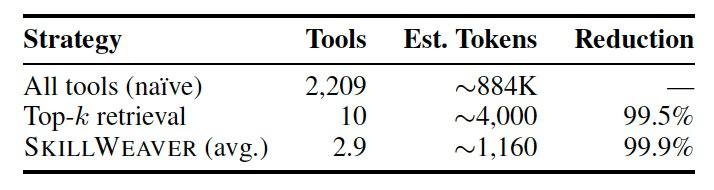
To evaluate performance, the researchers created a benchmark called CompSkillBench containing 300 multi-step queries, using a skill library of 2,209 skills from the public MCP ecosystem, covering 24 functional categories including cloud infrastructure, finance, and databases. The core engine uses the Qwen2.5-7B-Instruct model for task decomposition and the MiniLM semantic search retriever to find tools. Experiments show that in a standard setting without SAD, the 7B model achieved a decomposition accuracy of 51.0%, which jumped to 67.7% after activating the SAD feedback loop, and the larger Qwen-Max model reached 92%. On difficult tasks requiring four to five skills, SAD improved accuracy by 50%. Compared to the LLM-Direct method, which exposes all tools to the model, SkillWeaver's retrieval and rerouting significantly improved accuracy and reduced context window consumption per query from approximately 884,000 tokens to about 1,160 tokens, a reduction of 99.9%.
The research team noted that the framework is built on readily available open-source components, including the all-MiniLM-L6-v2 embedding model and FAISS index, and embedding and indexing 2,209 skills takes only 15 seconds. Developers can implement it themselves using orchestration libraries such as LangChain and LlamaIndex. Currently, the execution phase of SkillWeaver lacks error recovery capabilities; if an API call fails in the second step, it can cause the chain to break. The team recommends that production deployments build their own fallback and retry mechanisms.