
en.Wedoany.com Reported - GitHub has launched an internal artificial intelligence analysis agent called Qubot, designed to allow employees to query any data model in the data warehouse using natural language and receive answers within seconds.
Large data and analytics organizations often struggle to provide self-service access to data and insights. GitHub has dozens of internal product teams, making it challenging to offer dedicated analytical support, so many teams have to solve data analysis problems on their own. Although there is a wealth of valuable product telemetry data available for decision-making, determining the data model, granularity, and filters to use, writing queries, and validating results without the support of a data analyst has always been a difficult task.
Qubot, as an internal analysis agent based on GitHub Copilot, allows any Hubber (i.e., GitHub employee) to ask questions in natural language, such as "Which user group has the highest retention rate for this feature?" or "Which product contributed the most to the improvement of this metric last week?" This tool is not a replacement for reporting tools or dashboards but is suitable for exploratory questions, with zero maintenance costs, helping teams quickly become familiar with unfamiliar datasets.
Qubot's architecture consists of three main components: the user interface, the context layer, and the query engine.
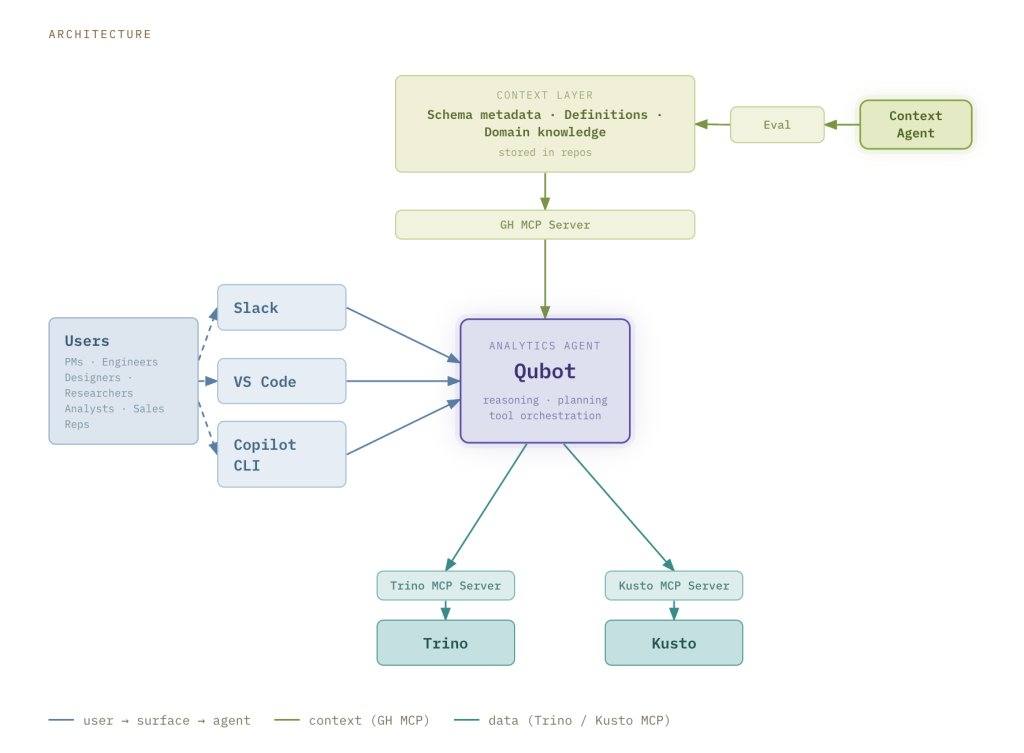
The user interface is accessible via Slack, VS Code, and the Copilot CLI. The Slack interface requires no configuration; when someone asks a question in the Qubot Slack channel, the system generates a Qubot instance, and the answer is displayed directly in Slack, allowing users to share results and iteratively refine questions. Results are also stored as Markdown reports in pull requests. Qubot can be used as a plugin in VS Code and the Copilot CLI after installation.
The context layer is built in a federated manner, with knowledge tailored to data types. For raw event (bronze layer) data, it has telemetry context contributed by product teams; for fact and dimension (silver layer) data, it has query examples and usage guides maintained by the data and analytics team; for gold layer data curated for specific business use cases, it has business rules and metric definitions. The ETL pipeline enriches the context layer with additional signals and derived metadata, loaded at runtime via the GitHub MCP server.
The context agent simplifies federated context contribution. Teams can contribute context through standardized templates or by referencing repositories, and the agent ingests, organizes, and normalizes the information into a structured format. Every change to the context layer or agent configuration is measured by an evaluation framework before release, which includes carefully designed test cases, automated run orchestration, and statistical aggregation components to measure response accuracy, latency, and capture regression issues.
The query engine connects to Kusto and Trino via the MCP server. Kusto is fast and suitable for exploratory queries on recent event data; Trino handles complex joins and deeper historical analysis. Qubot uses Kusto by default and automatically switches to Trino when needed.
Qubot has been widely adopted at GitHub, with hundreds of users executing thousands of queries. The number of questions in the data and analytics channel has significantly decreased, allowing employees to explore data more independently. The context layer has become key to enhancing Copilot's reasoning capabilities; well-structured context not only makes Qubot more accurate but also triples the speed of returning correct answers.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










