en.Wedoany.com Reported - Spatial-TTT, a multimodal spatial intelligence work led by Tsinghua University PhD student Liu Fangfu as the first author and completed in collaboration with multiple researchers, has been officially accepted by the top computer vision conference ECCV 2026. This work focuses on solving the streaming spatial intelligence challenge of multimodal large models in real physical environments—specifically, how a model can form and continuously update spatial memory in an ever-changing video stream, rather than treating each input as an independent segment.
Real-world scenarios such as robot navigation, autonomous driving, and augmented reality require models to possess capabilities far beyond static image understanding. Traditional methods, when processing long video streams lasting tens of minutes or even hours, suffer from fragmented spatial understanding due to the lack of effective online memory update mechanisms. Spatial-TTT is proposed to address this challenge by introducing the concept of Test-Time Training (TTT) into the spatial intelligence domain, allowing the model to update its internal parameters while watching videos during inference.
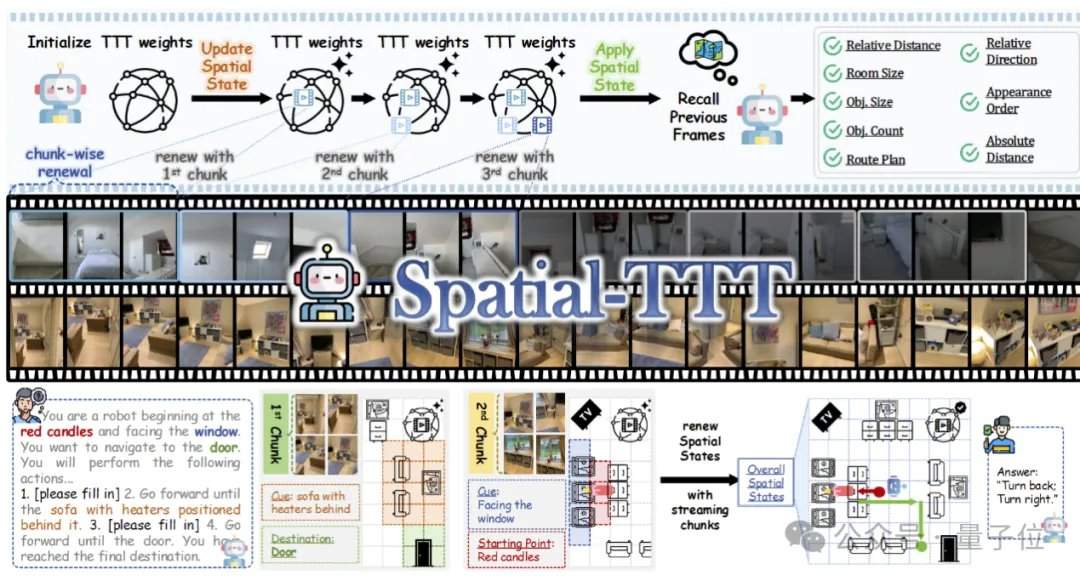
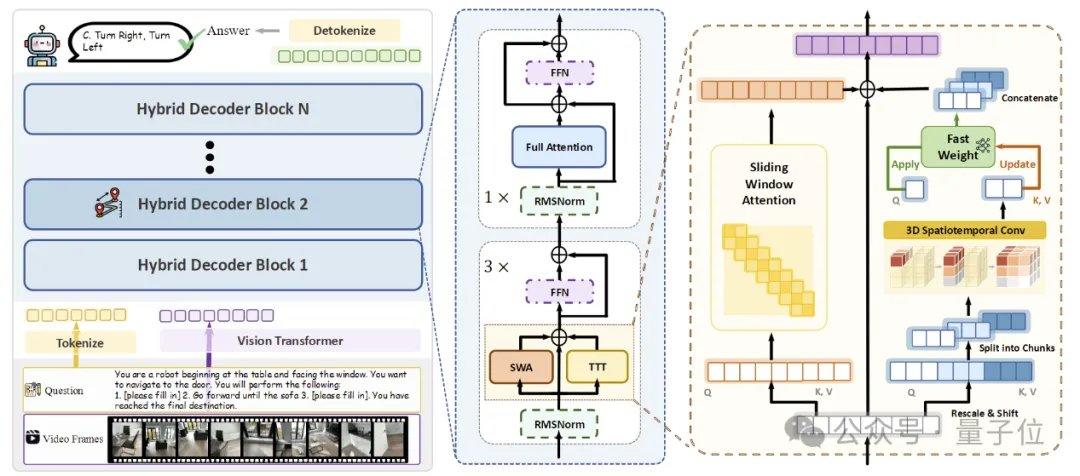
To achieve efficient streaming spatial memory, the research team proposed three key technologies. The first is a hybrid TTT architecture, where TTT layers and standard self-attention anchoring layers are interleaved in a 3:1 ratio within the decoder. The former is responsible for writing long-range information into fast weights, while the latter maintains the pretrained model's cross-modal alignment and semantic reasoning capabilities. The second is a spatial prediction mechanism, which introduces lightweight 3D spatiotemporal convolutions in the TTT branch to enable the model to learn predictive relationships between spatiotemporal contexts, enhancing the stability of online updates. The third is dense scene description supervision, which constructs scene description data covering global context, object categories, and spatial relationships to train the model to shift from "local question answering" to "maintaining global 3D memory."
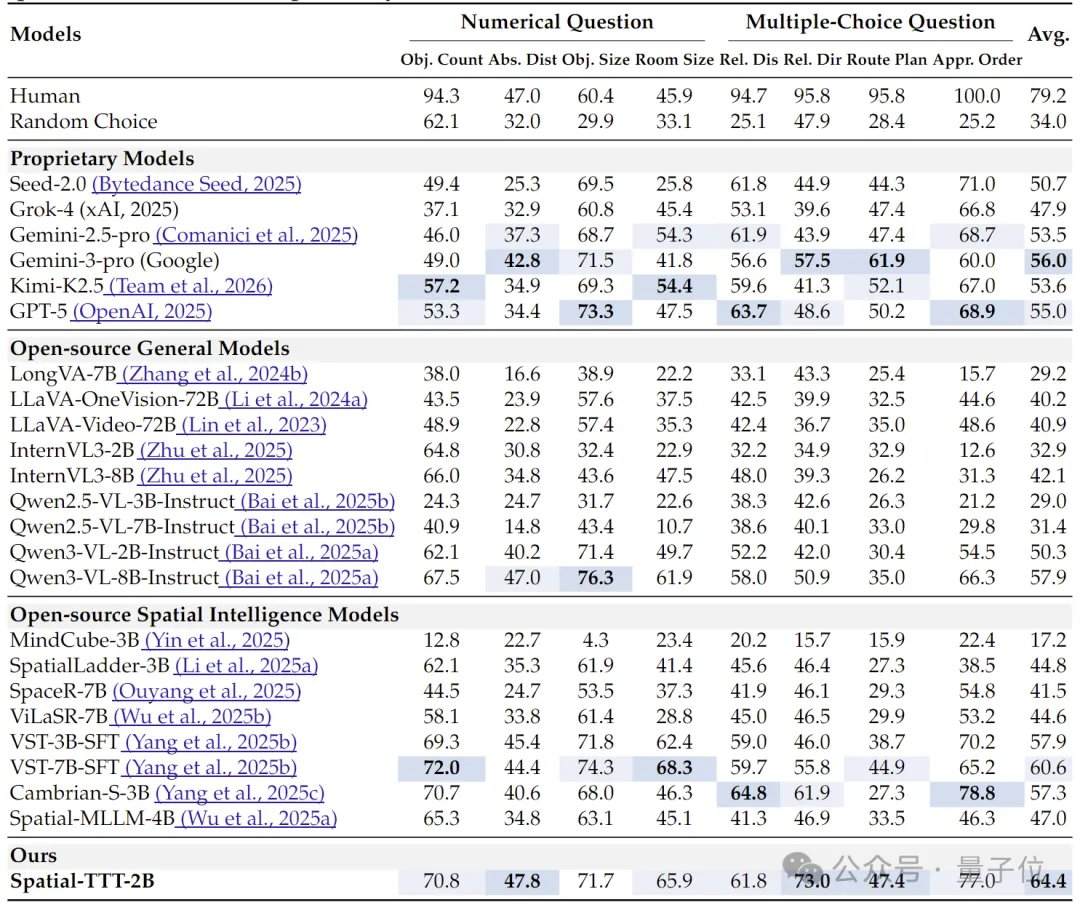
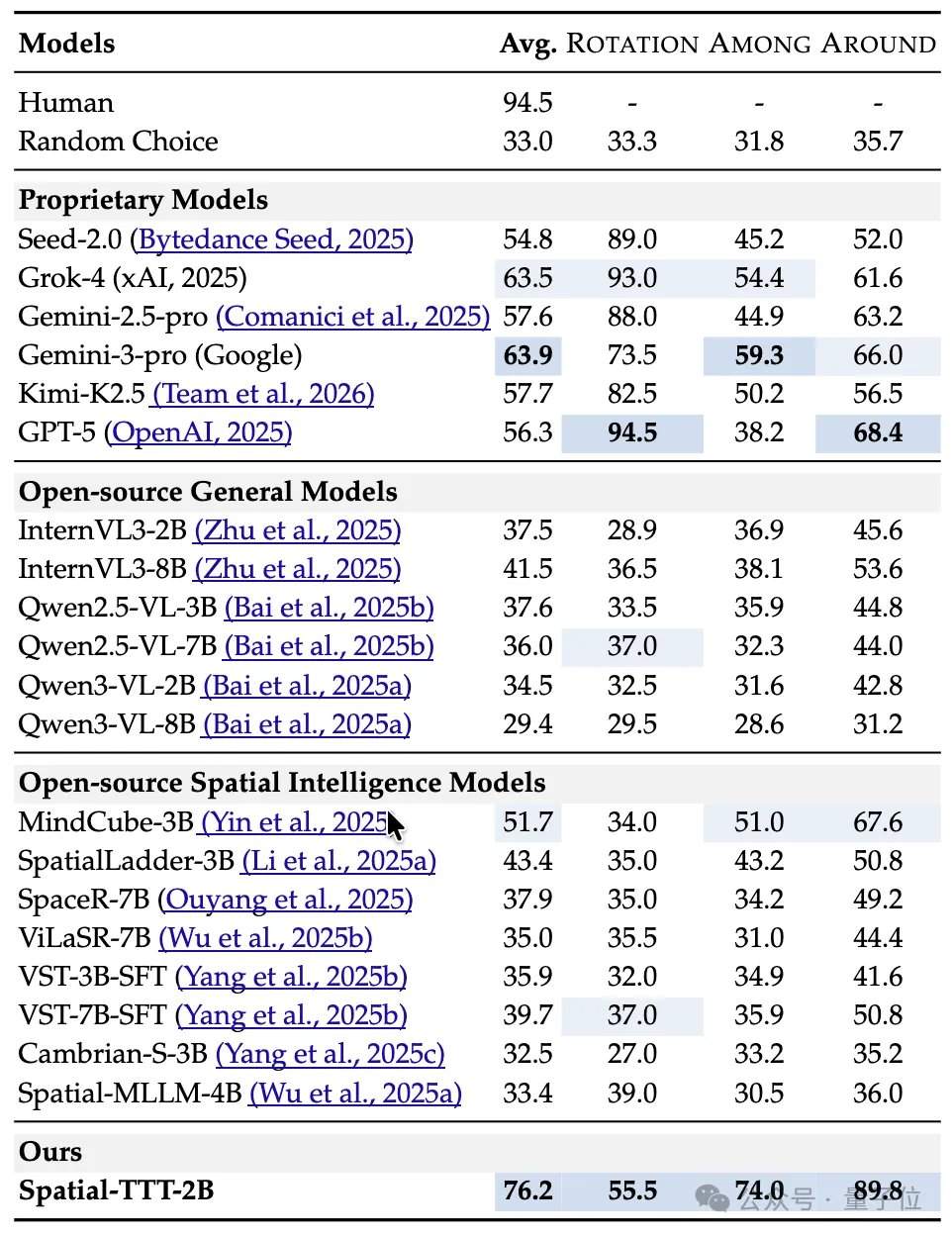
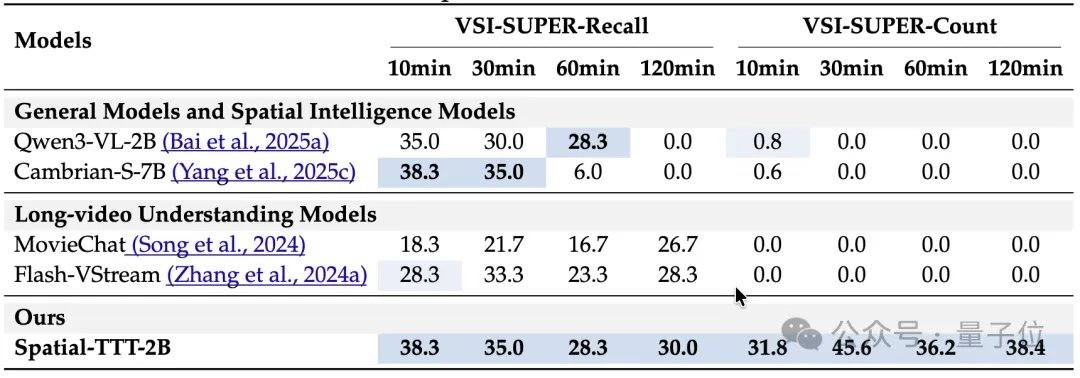
In terms of experimental results, Spatial-TTT, with only 2B parameters, demonstrated significant advantages across multiple specialized spatial intelligence benchmarks. On VSI-Bench, it achieved an average score of 64.4, surpassing closed-source models such as GPT-5 and Gemini-3-pro. On the MindCube-Tiny benchmark, which tests multi-view fine-grained spatial reasoning, Spatial-TTT achieved an accuracy of 76.2%, outperforming Gemini-3-pro (63.9%) by 12 percentage points and the representative open-source spatial model MindCube-3B (51.7%) by nearly 25 percentage points. In the VSI-SUPER series of tasks, which test long-term memory, the model stably processed streaming videos of up to 120 minutes. On the VSI-SUPER-Count task, Spatial-TTT scored 31.8, 45.6, 36.2, and 38.4 on videos of 10, 30, 60, and 120 minutes, respectively.
Efficiency analysis shows that under a 1024-frame input setting, Spatial-TTT-2B has a peak GPU memory usage of 11.9GB and a theoretical computation of 799.4 TFLOPs, achieving over 40% savings in both memory and computational resources compared to industry-leading baseline models. Ablation studies further confirm that the performance improvement stems from the synergistic effect of the hybrid architecture, spatial prediction mechanism, and dense supervision signals. Specifically, removing the spatial prediction mechanism drops the VSI-Bench average score from 64.4 to 62.1; removing the dense scene description supervision reduces it to 61.3; and completely removing the hybrid architecture, using only a pure TTT structure, brings the average score down to 53.9.
This research, accepted by ECCV 2026, provides a new technical pathway for physical artificial intelligence systems requiring long-term continuous operation. By enabling the model to continuously accumulate, correct, and utilize spatial information, future intelligent agents will no longer face fragmented frames but will be able to construct a continuous, understandable internal world model in which they can act.
Paper link: https://arxiv.org/pdf/2603.12255
Project page: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com