
en.Wedoany.com Reported - On June 22, Baidu open-sourced the Unlimited OCR model, aiming to solve the problem of end-to-end OCR models slowing down as they generate longer outputs when parsing long documents. The model has a total of 3 billion parameters, with only 500 million parameters activated during inference.
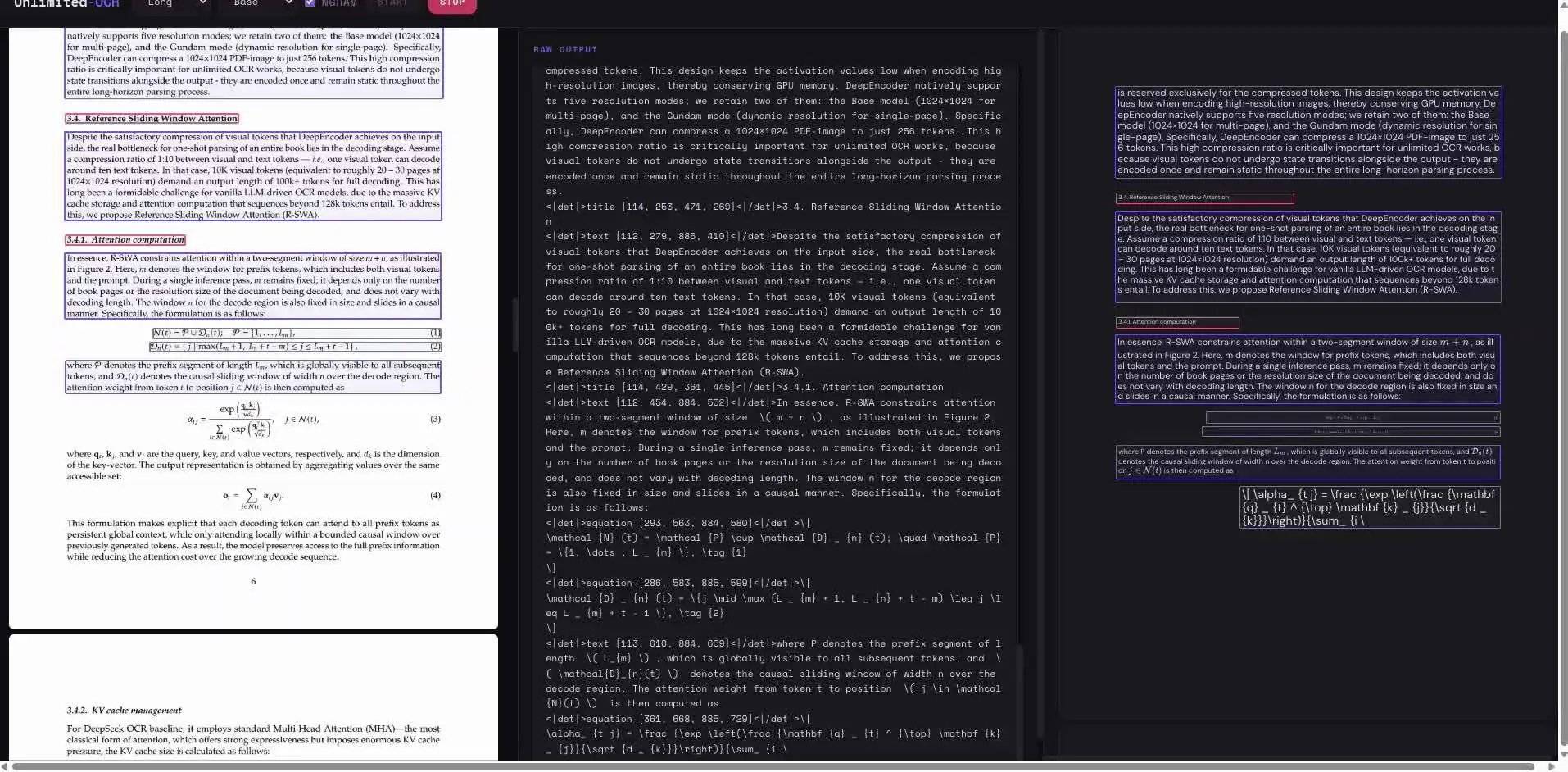
End-to-end OCR models adopt a unified neural network architecture, integrating text detection and character recognition into a single system, directly mapping input images to text sequence outputs, eliminating the traditional process of first detecting text boxes and then recognizing them separately. Mainstream end-to-end OCR models expand the key-value (KV) cache with each generated token, leading to continuously increasing memory usage and latency, causing users to perceive that multi-page document parsing slows down progressively.
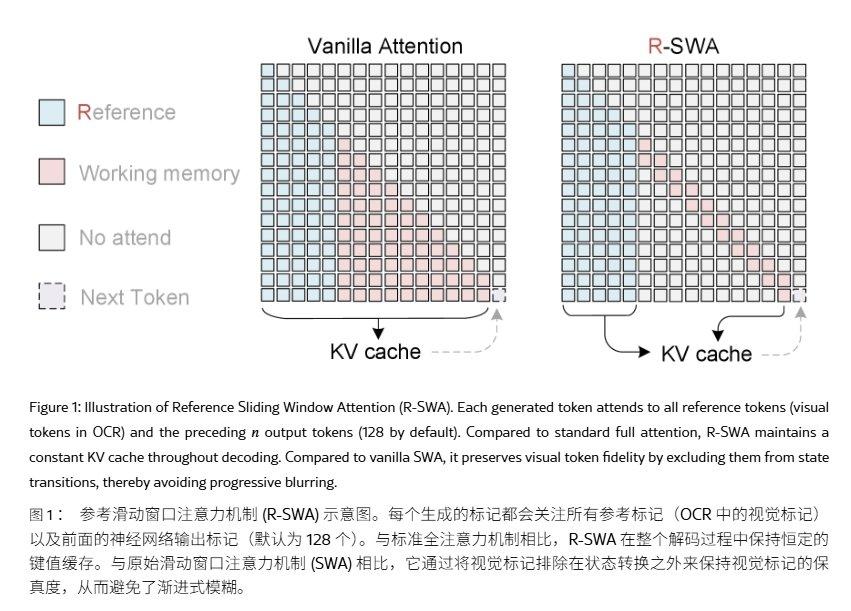
Unlimited OCR continues the DeepSeek OCR architecture, retaining the DeepEncoder and Mixture of Experts (MoE) decoder. The encoding side uses a two-stage visual encoding process, performing 16x token compression during the connection stage, compressing a 1024×1024 PDF image into 256 visual tokens, reducing the prefill burden at the source.
In terms of training, Unlimited OCR continues training for 4000 steps based on the DeepSeek OCR checkpoint, freezing the DeepEncoder and training only the decoder. The training data consists of approximately 2 million document samples, running on 8×16 A800 GPUs. The data ratio is roughly 9:1 for single-page to multi-page samples, with multi-page samples obtained through concatenation.
Benchmark tests show that Unlimited OCR achieves an overall score of 93.23 on OmniDocBench v1.5, higher than DeepSeek OCR's 87.01 and DeepSeek OCR 2's 89.17. Its text edit distance is 0.038, formula CDM is 92.61, table TEDS is 90.93, and reading order edit distance is 0.045. On OmniDocBench v1.6, the model's overall score further reaches 93.92.

This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com









