
en.Wedoany.com Reported - Researchers from IMDEA Software Institute, Nokia Bell Labs, Complutense University of Madrid, Aalto University, and Quobly have developed an FPGA-based hardware architecture for real-time decoding of quantum LDPC codes. Published on ArXiv, the design manages correlated error arrays through structural layout, optimizing latency, physical area, and power consumption, addressing the classical computing processing bottleneck that challenges the physical scaling of quantum error correction layers. The architecture utilizes targeted resource reuse loops rather than unlimited hardware parallelization to handle complex multi-qubit syndrome dependencies.
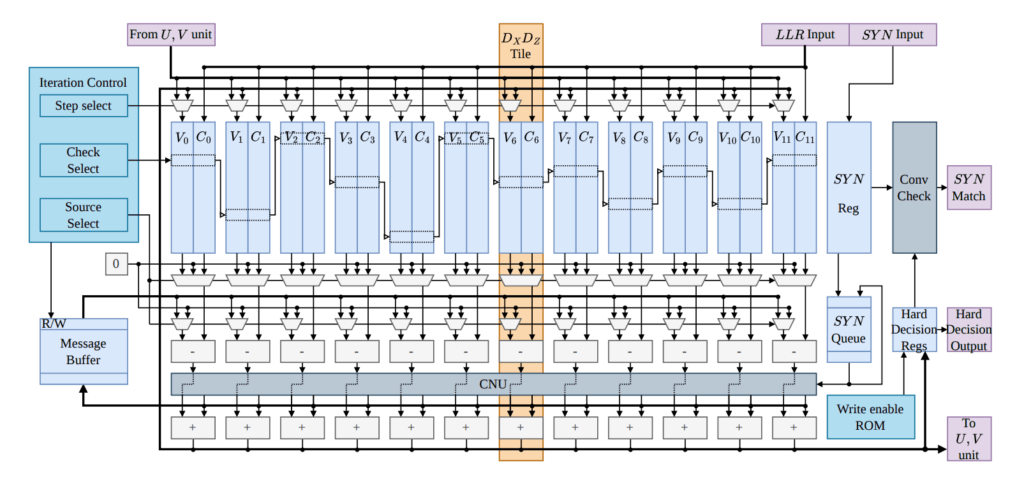
The internal decoder layout directly maps to a specialized Graph Augmentation and Rewiring Inference (GARI) framework. Standard decoding routines typically process spatial X and Z error coordinates independently, reducing tracking fidelity when phase and bit-flip parameters are linked through combined Y-type faults. The GARI transformation alters the underlying detector error model matrix by separating correlated variables and eliminating short 4-cycles involving Y errors, replacing the entanglement graph with structured U and V coordinate dependencies. This algebraic reconstruction allows the hardware to distribute the joint decoding task across decoupled execution paths, suppressing harmful message correlations while maintaining iterative information exchange between error domains.
To execute the reconstructed matrix, the architecture partitions processing tasks into a Belief Propagation (BP) core and a parallelized tracking module. The primary DX and DZ matrices are routed through a memory-based, serially scheduled BP unit that sequentially updates computational parameters according to normalized min-sum rules. Independent check structures for the U and V matrices are parallelized within separate hardware tiles, processing intervals synchronized with the serial core. Modular cross-interconnects operate as N-to-N pipelined routers using binary radix sort stages, bypassing explicit classical controller logic to prevent routing congestion and data bus stalls.
The hardware implementation was evaluated on an AMD VCU19P FPGA and mapped to a VU29P FPGA fabric for decoding the [[144,12,12]] bivariate bicycle code within a window of 12 consecutive syndrome measurement rounds. The architecture applies numerical quantization constraints, limiting input log-likelihood ratios (LLRs) to 6 bits, check node messages to 8 bits, and variable node values to 10 bits, while approximating the numerical precision of classical floating-point tracking models. Operating at approximately 274 MHz via AXI-Stream ports, the pipelined execution loop provides an average decoding latency of 596 nanoseconds per round, meeting real-time decoding constraints under hardware-realistic correlated noise distributions.
A single core occupies a constrained area, including 7.5% of total logic lookup tables (LUTs), 3.5% of registers, and 26% of internal block RAM (BRAM) elements, with partial mapping to URAM blocks to reduce memory pressure. This resource efficiency enables a combined configuration of three decoders to run simultaneously on a single VCU19P FPGA board. A full tracking combination of 24 concurrent decoders can be deployed across eight physical hardware devices, compared to the 48 boards required by a fully parallelized alternative architecture.
Detailed silicon resource allocation, matrix transformation derivation, and routing latency benchmarks are available in the full preprint provided on arXiv.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










