

A new advancement in robotics has emerged as researchers from Purdue University and LightSpeed Studios introduced a training-free computational technique that generates inspection plans for robots based solely on written descriptions, providing guidance for robot actions in specific environments.
Robotics has automated numerous real-world tasks, from industrial manufacturing and packaging to minimally invasive surgery, and is also used to inspect hazardous or hard-to-access infrastructure such as tunnels and dams. However, most inspection work still relies on humans. While computer scientists have recently attempted to develop computational models for planning robot inspection trajectories, room for improvement remains.
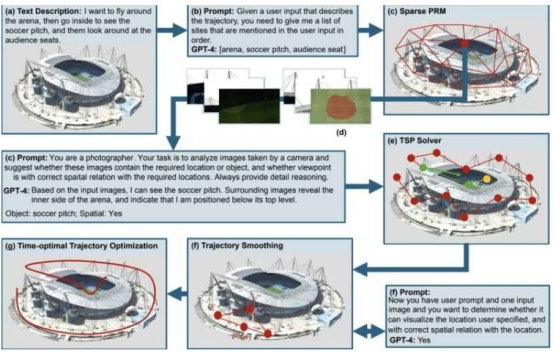
The method proposed by the Purdue and LightSpeed Studios team is detailed in a paper published on the arXiv preprint server. It relies on a vision-language model (VLM) capable of processing both images and written text. First author Xingpeng Sun stated that, inspired by real-world challenges in automated inspection, efficiently generating task-specific inspection routes is critical for applications like infrastructure monitoring. Unlike most existing methods that use VLMs for exploring unknown environments, their approach leverages VLMs to navigate known 3D scenes and perform fine-grained robot inspection planning using natural language instructions.
The primary goal is to develop a computational model that generates customized inspection plans based on specific requirements without requiring further fine-tuning of the VLM on large datasets, as most machine-learning-based generative models do. Sun explained that the model uses a pre-trained VLM (e.g., GPT-4o) to interpret natural language descriptions of inspection goals and related images, evaluates candidate viewpoints based on semantic alignment, uses GPT-4o to infer relative spatial relationships via multi-view image reasoning, and then solves a traveling salesman problem (TSP) via mixed-integer programming to generate an optimized 3D inspection trajectory, accounting for semantic relevance, spatial ordering, and positional constraints.
Sun and his advisor Dr. Aniket Bera stated that this novel training-free VLM-based robot inspection planning method effectively translates natural language queries into smooth and accurate 3D robot inspection trajectories, with advanced VLMs like GPT-4o demonstrating strong spatial reasoning when interpreting multi-view images.
The researchers evaluated the model through a series of tests, asking it to create inspection plans for various real-world environments and inputting corresponding images. Results showed the model successfully generated smooth trajectories and optimal camera viewpoints, predicting spatial relationships with over 90% accuracy.
As part of future plans, the team will further develop and test the method to enhance performance across diverse environments and scenarios, followed by evaluation on real robot systems and eventual deployment in real-world settings. Sun and Dr. Bera added that next steps include extending the method to more complex 3D scenes, integrating active visual feedback to dynamically refine plans, and combining perception with robot control for closed-loop physical inspection deployment.