en.Wedoany.com Reported - On June 1, Chinese AI company MiniMax launched its next-generation general-purpose model, MiniMax M3. Built on the proprietary MiniMax Sparse Attention architecture, the API supports a context window of up to 1M tokens, with at least 512K tokens guaranteed. It is primarily designed for long-range agents, complex coding tasks, and native multimodal applications.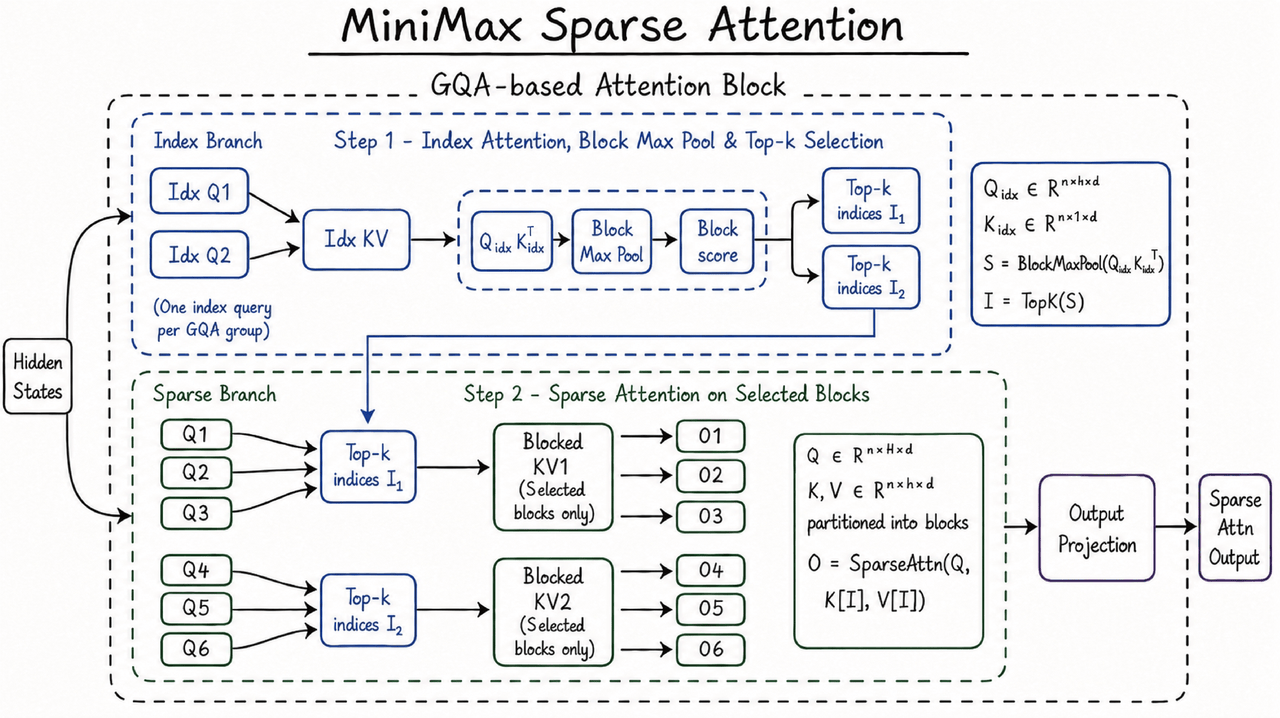
The core shift in MiniMax M3 lies in moving long-context capabilities from "parameter metrics" to "engineering task execution." As large models enter the agent phase, they must handle not just single-turn Q&A or short text generation, but long-thread tasks interweaving code repositories, product documentation, task logs, tool invocation records, and image/video information. A 1M-token context window allows MiniMax M3 to retain more upstream and downstream information within a single task chain, reducing information loss from frequent truncation, repeated summarization, and external retrieval. For software development, scientific research replication, enterprise knowledge base Q&A, long video comprehension, and complex office automation, long context is becoming a critical foundation for stable production deployment.
This capability is supported by MiniMax's proprietary MiniMax Sparse Attention (MSA) architecture. Traditional full-attention mechanisms face rapidly increasing computational costs as context length grows. MSA improves computational efficiency under long contexts through sparse attention, enabling MiniMax M3 to maintain usable inference performance within a million-token context window. Official data shows that at a 1M context length, M3's per-token computation is approximately 1/20 of the previous generation model, with prefill speed improved by over 9 times and decoding speed by over 15 times. For developers and enterprise users, such efficiency gains directly impact API costs, response speed, and sustained execution of long tasks, determining whether MiniMax M3 can move from demo scenarios to higher-frequency business calls.
MiniMax M3 also emphasizes coding and agent capabilities. Software engineering tasks have become a key battleground for large model capabilities, as real development workflows typically involve requirement clarification, code modification, test feedback, tool invocation, version iteration, and multi-round collaboration. MiniMax disclosed that M3 achieved high scores in benchmarks such as SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard, and MCP Atlas, and trained the model to adapt to continuous collaboration scenarios through a user simulation framework. This direction indicates that MiniMax M3 is not just focused on improving "writing a piece of code," but aims to cover the entire development chain from task decomposition, execution, and verification to iterative refinement.
Multimodality is also a key capability of MiniMax M3. The model incorporates mixed-modal data from early training stages, enabling text, image, and video information to be processed collaboratively within unified tasks. In official examples, MiniMax M3 is used for long-cycle tasks such as paper replication experiments, CUDA operator optimization, and automation of model training workflows, demonstrating the combined value of long context, coding ability, tool invocation, and multimodal understanding. For enterprise AI applications, such combined capabilities mean the model can simultaneously read documents, understand charts, analyze logs, generate code, and invoke tools, expanding the boundaries of agent applications from "single-point capabilities" to "cross-step execution."
The launch of MiniMax M3 also reflects that competition among Chinese large models is shifting from pure model parameters, pricing, and general conversational experience toward capabilities closer to production environments, such as long context, agent execution, software engineering, and multimodal integration. As enterprises integrate large models into R&D, operations, customer service, office, and knowledge management workflows, model vendors must simultaneously address performance, cost, context capacity, stability, and tool ecosystem issues. MiniMax's investment in million-token context and the MSA architecture indicates that long-task agents are becoming the next competitive focus for the commercial deployment of large models.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com