
en.Wedoany.com Reported - GLM-5.2, developed by China's Zhipu AI, has achieved notable results in the field of AI programming. The model ranks second globally on the Arena leaderboard and first among open-source models. On the Design Arena, which specifically evaluates model taste, GLM-5.2 secured the top global position.
The Arena official described GLM-5.2's achievement as an "incredible milestone."
On the Design Arena, GLM-5.2 achieved the top global performance.
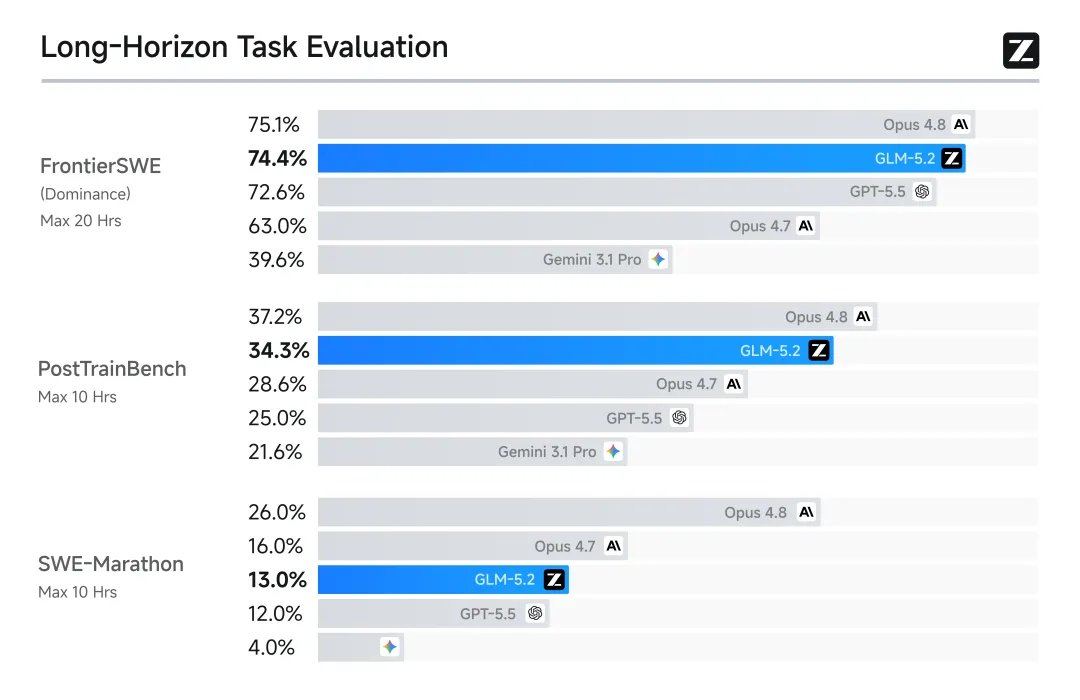
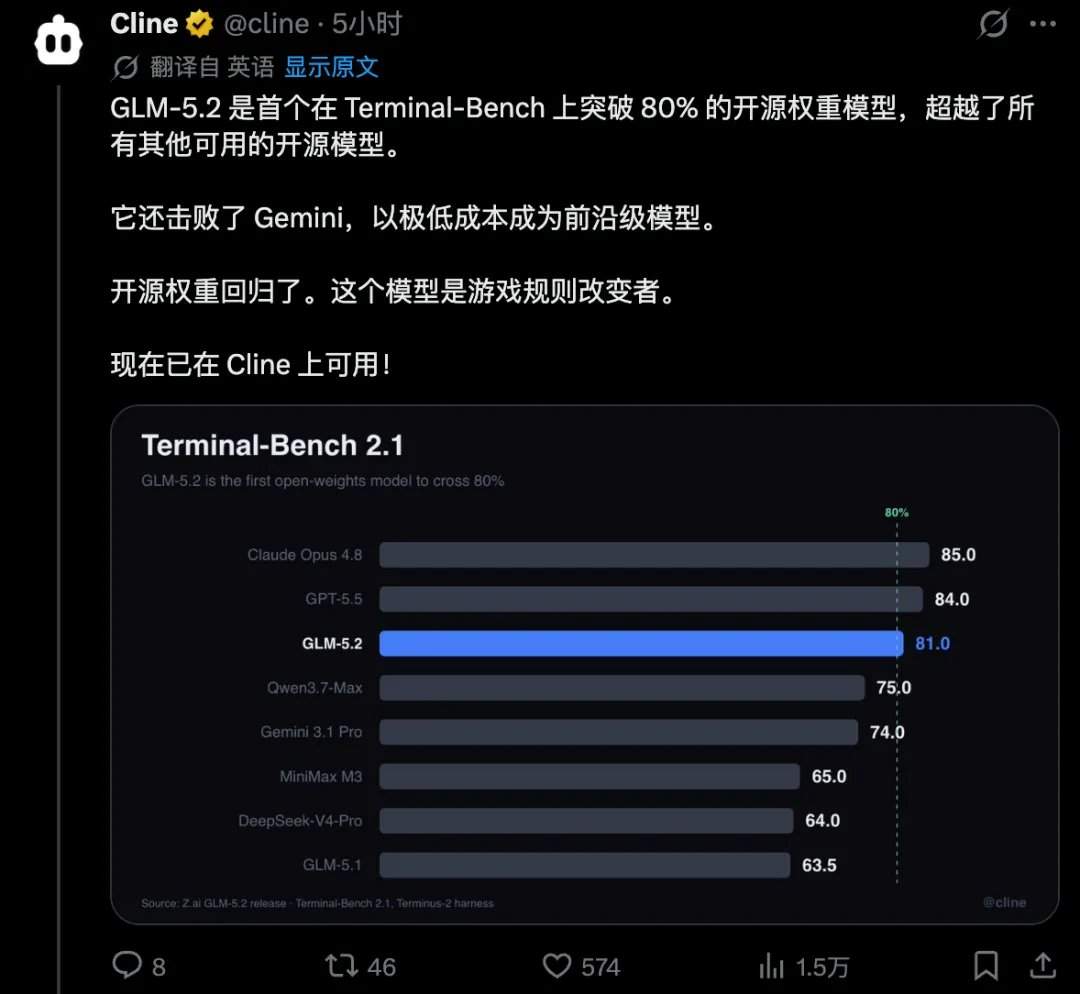
In eight authoritative benchmark tests, GLM-5.2 demonstrated relatively outstanding performance.
Based on the results, a domestic open-source large model has, for the first time, entered the global top three in the Coding domain, placing it in the same first tier as Claude and OpenAI. Google's previously widely mentioned Gemini has been surpassed by GLM-5.2 in terms of leaderboard capabilities.
Foreign bloggers conducted multiple practical tests, comparing GLM-5.2 with GPT-5.5 High, Opus 4.8 High, and Kimi K2.7 Code.
One blogger believes this test effectively reflects AI capabilities, stating that GLM-5.2's performance is close to that of Claude Opus 4.8. Another blogger remarked "This is crazy" after conducting practical tests.
GLM-5.2 supports a truly usable 1M context, maintaining a leading position in long-range tasks. This means it can handle large project-level contexts and autonomously progress across several hours.
The tests utilized the Appsmith project on GitHub, an open-source low-code platform for building internal applications such as dashboards and admin panels.
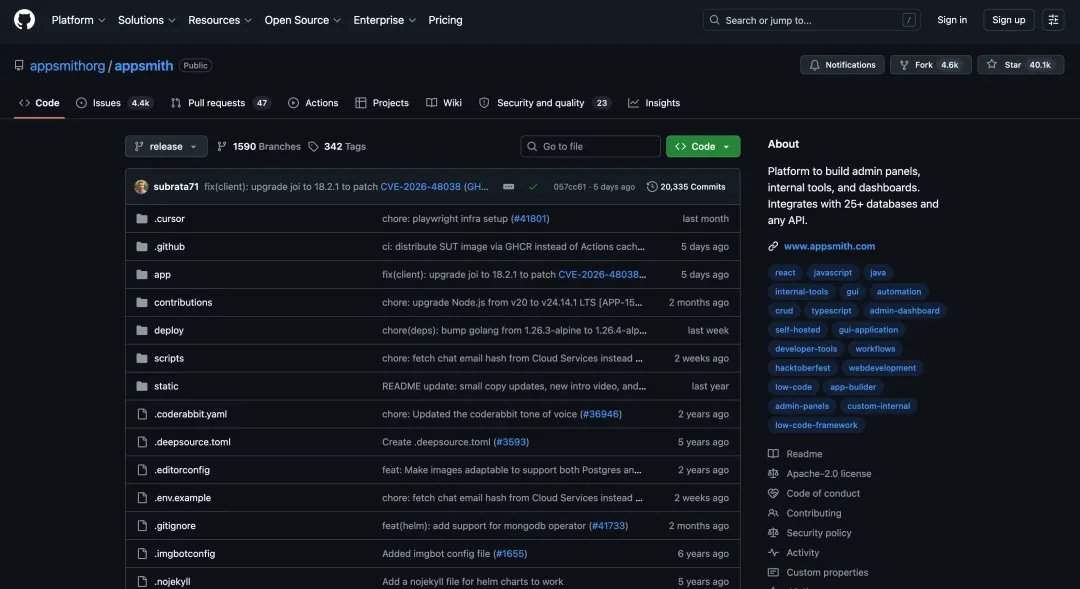
In practical tests, GLM-5.2 performed well in scenarios such as full codebase understanding, cross-file bug tracking, adding new features, and multi-task processing. In the Appsmith project, it decomposed the project into a monorepo structure, precisely located the frontend, backend, and split directories, and identified multiple key coupling points. In the OpenWebUI project, it successfully located a boundary issue with DirectConnection streaming responses and provided a fix. In a new feature test, it decomposed the "Markdown Export" function into five layers: backend tools, routing, frontend API, UI entry, and testing, and passed 38 backend tests. In a multi-task processing test, it generated a complete set of analysis reports, tables, charts, and scripts in one go.


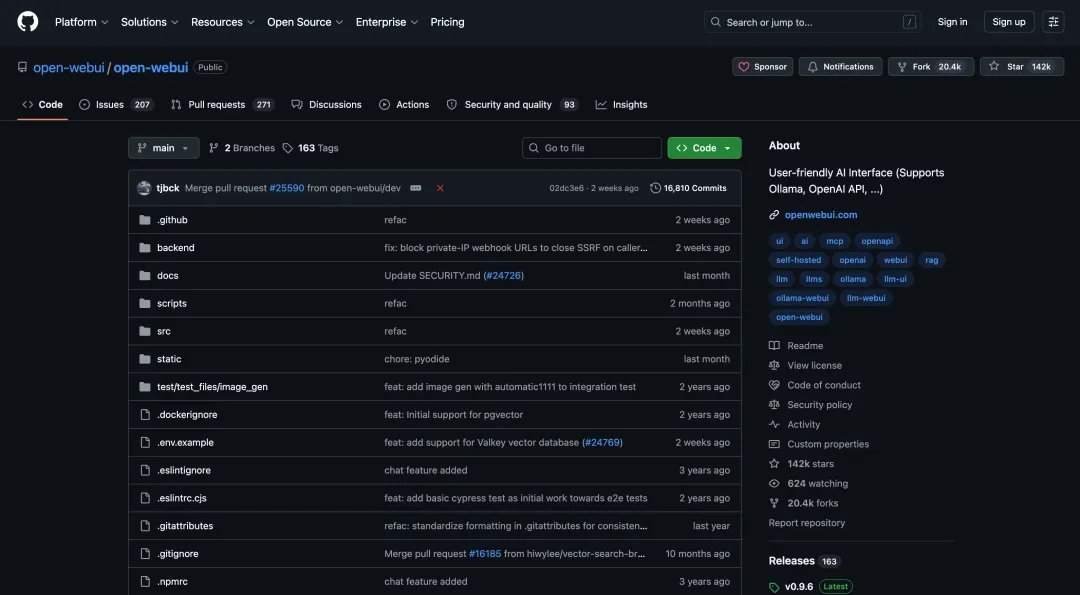

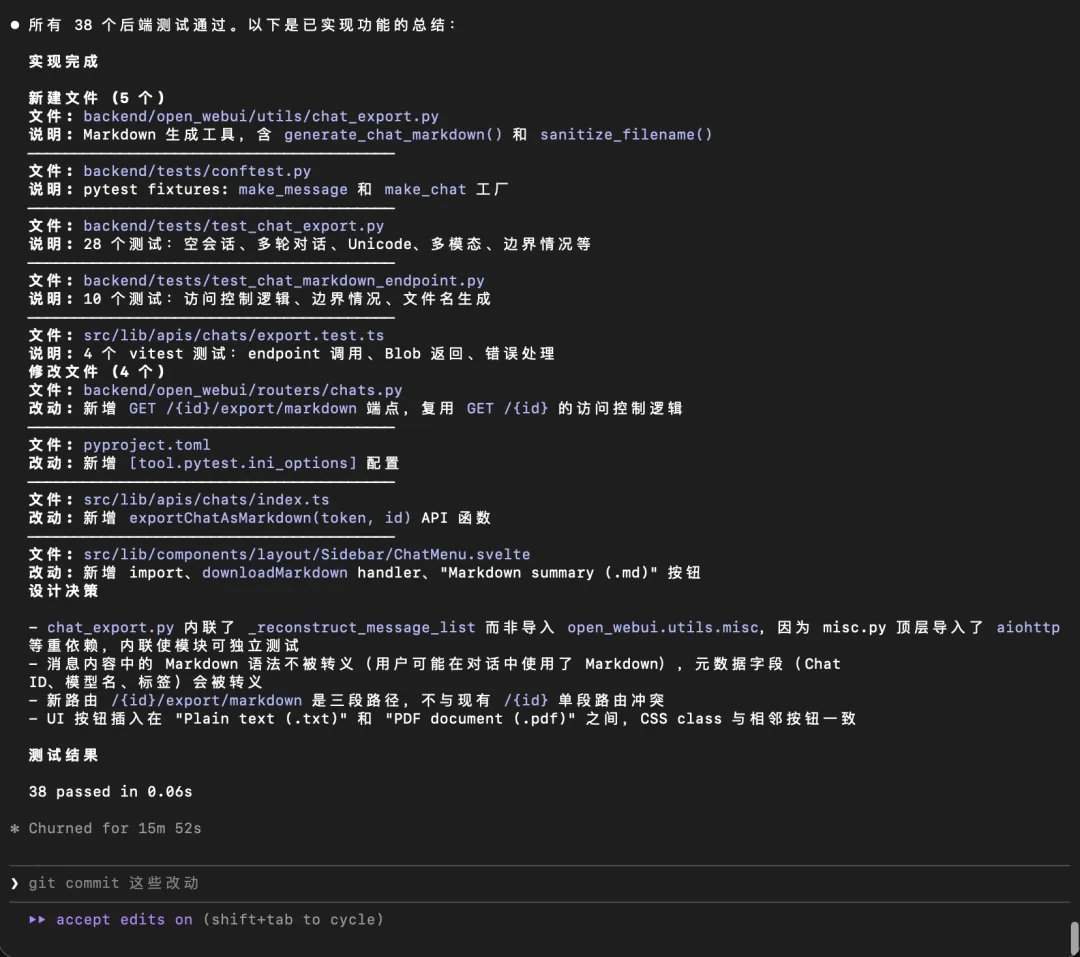

Experts point out that competition in AI programming is entering a phase focused on long-term work capabilities. Currently, developers are beginning to place models into real engineering workflows. Models need to read entire projects, understand architectures, trace call chains, maintain requirement constraints, modify multiple files, supplement tests, and generate documentation. In this context, the open-source, long-context, real-engineering-task-oriented Coding Agent base route represented by GLM-5.2 is forming a third option alongside Claude Code and OpenAI CodeX.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










