
en.Wedoany.com Reported - Chinese AI company DeepSeek, in collaboration with Peking University, released the DSpark inference acceleration framework on June 27, proposing a new approach to address inference efficiency bottlenecks in high-concurrency large model services. Based on speculative decoding, the framework improves draft token quality and reduces invalid verification computations through a semi-autoregressive generation structure and a confidence-based dynamic verification mechanism. In the DeepSeek-V4 online service system, DSpark boosts inference speed by approximately 60%–85% compared to the baseline model and reduces throughput loss under high concurrency.
Speculative decoding is one of the key approaches to accelerating large model inference. When generating text, large models typically predict tokens one by one, with the next token only computed after the previous one is generated. This autoregressive method ensures contextual coherence but makes it difficult to fully parallelize the inference process. The idea behind speculative decoding is to first have a lightweight draft model generate several candidate tokens in advance, which are then verified by the target large model. If the candidate tokens are accepted, multiple generation steps can be advanced at once, thereby improving overall output speed.
The problem is that while existing parallel draft generation methods can produce longer token blocks at once, the lack of correlation between tokens makes subsequent tokens more likely to deviate from the target model's distribution, leading to a higher rejection rate. Rejected draft tokens not only fail to accelerate inference but also consume verification computational resources, creating additional waste, especially in high-concurrency online services. DSpark addresses this pain point by adding a lightweight sequential module to the parallel generation backbone, enhancing dependencies between draft tokens and increasing the acceptable length of candidate sequences.
The semi-autoregressive structure is the core design of DSpark. It neither fully reverts to token-by-token autoregression nor simply generates the entire draft block in a single parallel pass, but instead strikes a balance between parallel efficiency and sequence dependency. The parallel backbone quickly generates candidate blocks, while the lightweight sequential module supplements contextual relationships between adjacent tokens, bringing the draft model closer to the target model's generation path. This makes it easier for the target model to accept consecutive tokens during verification, allowing a single verification to advance over a longer generation distance.
Another key mechanism of DSpark is confidence-based dynamic verification. The success probability of drafts varies across different requests, contexts, and generation positions. If the system uses a fixed verification length, it wastes computation on low-success-rate requests and may fail to fully utilize acceptable drafts on high-success-rate requests. DSpark adaptively adjusts the verification length based on request success probability and system load, avoiding scenarios where "drafts with low acceptance rates are still verified at excessive lengths" and allocating computational resources more reasonably under high load.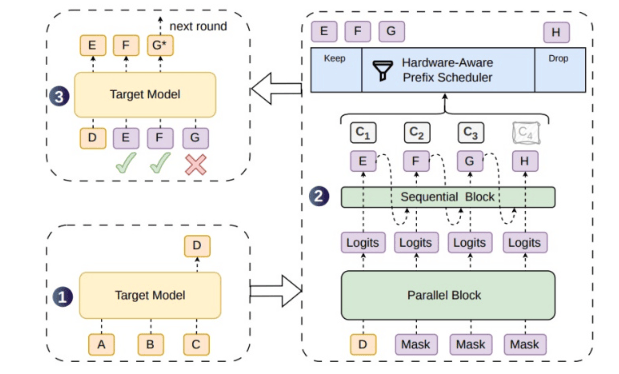
This mechanism is particularly important for online production environments. Offline test environments typically have more controllable requests and lower concurrency pressure, but real large model services simultaneously handle a large number of user requests with varying input lengths, task types, output styles, and generation difficulties. An inference acceleration framework that is only effective in small-scale experiments struggles to support commercial deployment. DSpark's 60%–85% inference speed improvement in the DeepSeek-V4 online system demonstrates that its design has been validated under real service pressure, rather than being merely optimized for laboratory metrics.
DSpark also improves high-concurrency throughput by increasing the acceptable generation length. The cost of large model services comes not only from single-request latency but also from the total throughput capacity of GPU clusters under high load. Higher draft quality means the target model accepts more tokens per verification, resulting in higher effective output per unit of computational resource. For API services, agent systems, code generation, search Q&A, and enterprise-level AI applications, reduced inference costs mean the same computational power can serve more requests or provide faster response times at the same cost.
DeepSeek has also open-sourced the model checkpoint and training framework DeepSpec, providing the community with a complete toolchain for further research on speculative decoding algorithms. DeepSpec includes draft model training, data preparation, evaluation scripts, and implementations of multiple algorithms, supporting the training and comparison of draft models such as DSpark, DFlash, and Eagle3. The significance of the open-source framework is that external developers and research institutions can reproduce, fine-tune, and evaluate it across different target models, task data, and service scenarios, advancing speculative decoding from a single-point algorithm to an engineering tool.
This achievement also reflects that competition in large models is expanding from model parameter scale to inference engineering efficiency. Model capability determines the upper limit of service, while inference speed and unit cost determine the pace of commercial deployment. As enterprise applications, agents, programming assistants, and multimodal systems enter high-frequency usage, users not only demand that models "answer well" but also "answer quickly, at low cost, and with stable concurrency." DSpark addresses the fundamental efficiency issues that arise when large models enter large-scale online services.
Future focus areas center on three aspects: first, whether DSpark can maintain stable acceleration across more model architectures and task types; second, whether the dynamic verification mechanism can further reduce invalid computation under ultra-high concurrency environments; and third, whether the community, following the open-sourcing of DeepSpec, will develop more specialized draft models based on DSpark for tasks such as code, mathematics, long texts, and agents. As inference-side costs become a core variable in the commercialization of large models, inference acceleration frameworks like DSpark will become an important component of AI infrastructure competition.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










