
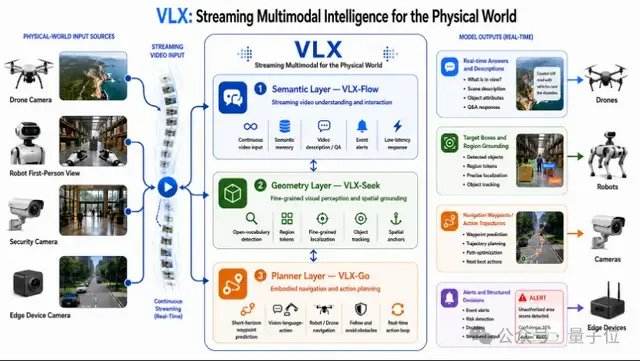
en.Wedoany.com Reported - Hangzhou-based AI company Om AI has launched the world's first on-device streaming multimodal model series, VLX, designed for the physical world. The series includes three models, to be released over three days: VLX-Flow handles real-time streaming perception, allowing video to flow continuously like water, with the model observing, thinking, and updating the world state in real time; VLX-Seek handles precise localization, moving from seeing to discerning, quickly locking onto targets; VLX-Go handles action decision-making, translating perception and localization results into real-world actions, specifying walking directions and operational steps.
These three models connect to form a closed-loop capability for multimodal models, from continuous perception and precise localization to action decision-making. Its native on-device design enables the model to truly run on edge devices such as phones, drones, and robots.
This is not Om AI's first foray into the vision-language domain. Last year, the company launched VLM-R1, the world's first open-source project to introduce the DeepSeek R1 reinforcement learning paradigm into vision-language models. It garnered over 2,000 GitHub Stars within 12 hours of launch, topped the GitHub global trending list within 48 hours, and has since accumulated over 6,000 Stars.
The VLX series is designed around two key concepts: on-device and streaming multimodal. Streaming multimodal refers to enabling AI to continuously and in real-time perceive the environment in the physical world, forming a complete capability chain from perception to precise localization to action. This differs from streaming multimodal in voice assistants, which emphasizes real-time human-AI interaction, whereas VLX focuses on AI continuously observing, judging, and driving actions in the physical world, bridging the gap from image understanding to task execution. With the rapid development of embodied intelligence, spatial intelligence, and video generation, vision-language models are no longer just capability modules for language models but are gradually becoming a new generation of infrastructure for spatial understanding, video understanding, and even action planning. Data from this year's CVPR shows that the proportion of papers related to vision-language models and multimodality has grown from 4.9% last year to 10.6%, making it one of the fastest-growing research directions in recent years, with real-time perception and localization being the two most noteworthy keywords.
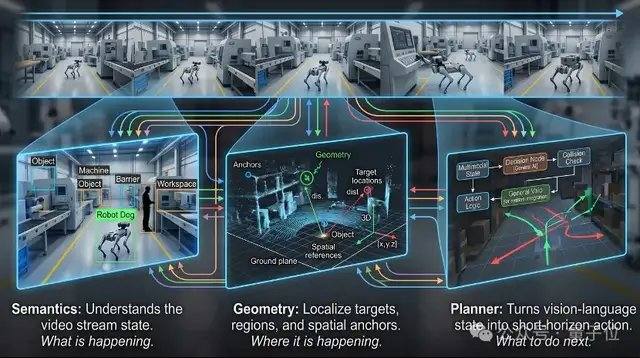
VLX-Flow handles continuous perception. In the real world, objects are constantly in motion, the environment changes continuously, and perspectives shift frequently; a one-time observation is insufficient for dynamic, open, and ever-changing environments. Traditional video models often cut entire videos into frames and feed them into the model at once for offline understanding. As videos lengthen, computational costs skyrocket, and earlier information is easily lost. Flow adopts streaming processing, where frames flow in continuously like water. It relies on incremental encoding and caching mechanisms to constantly update the visual state, without needing to recompute history or losing memory as the video grows longer. Technically, Flow uses Linear Attention instead of standard Attention, combined with a dual-layer memory mechanism, allowing the video stream to continuously enter the model without causing memory explosion due to growing context.

VLX-Seek handles fine-grained perception. While many general vision-language models excel at high-level semantic understanding, they perform poorly on tasks like precise localization, open-vocabulary detection, and fine-grained grounding. Traditional methods use an autoregressive approach, predicting target positions coordinate by coordinate, which is slow and prone to errors. Seek changes this approach: instead of guessing coordinates, it first generates candidate regions, then performs retrieval and matching, turning the localization process into region selection. Specifically, Seek uses Region Tokens to replace traditional coordinate generation, significantly reducing model size and on-device deployment costs while maintaining recognition capability. This method aligns better with visual perception tasks, allowing it to maintain stable performance on tasks like open-vocabulary detection, fine-grained grounding, and real-time tracking, even with a smaller model size.

VLX-Go handles action. Traditional vision-language models, even if they know a target is to the front-left, mostly end up providing textual answers. Actually moving towards it, navigating around obstacles, and continuously following the target still requires an additional control system. Go takes monocular video, historical visual memory, and natural language instructions as input, directly processing them into short-term waypoints executable by a robot, predicting how to move in the immediate future, rather than just outputting textual suggestions. Go combines offline trajectory learning and online reinforcement learning, continuously refining its motion strategy in a simulated closed loop, enabling the robot to continuously adjust its trajectory based on real-time visual feedback, maintaining stable performance in tasks like target following, navigation, and dynamic obstacle avoidance. To meet the real-time control needs of edge devices, Go adopts a lightweight short-term waypoint prediction scheme, requiring only 0.6B parameters for real-time motion planning.
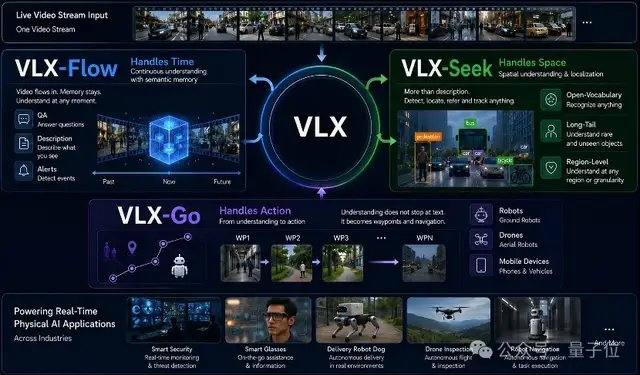
The Flow, Seek, and Go models are not independent of each other; they share the same base model and perform end-to-end collaboration on the same video stream. From continuous perception to precise localization to action decision-making, the three together form a complete capability chain for VLX targeting the physical world.
For physical world devices like robots, drones, and cameras, on-device deployment is a prerequisite for the model's practical application. While many cloud-based multimodal models are already powerful, they are not inherently suitable for robotics and embodied scenarios because the real world is continuous, dynamic, and resource-constrained. The common industry approach is to first train the largest possible model, then compress it for edge deployment through quantization, distillation, etc. VLX takes a different path, redesigning the entire system from the outset according to the computational constraints of edge devices. The model architecture, inference method, and deployment pipeline are all designed around real-time video streams and edge devices.
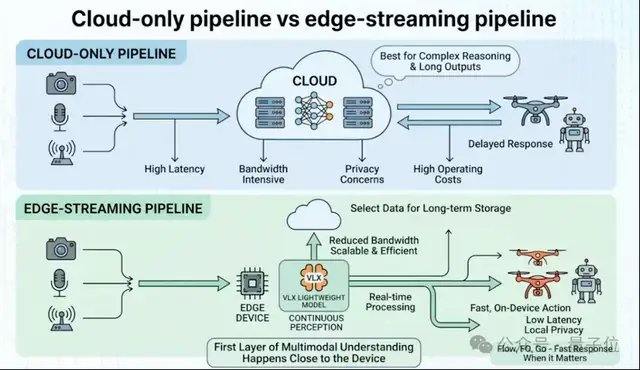
Data shows that VLX-Flow processes a single video stream in as fast as 0.06 seconds, while stably handling multiple video streams; VLX-Go achieves navigation performance superior to larger models with only about one-tenth the parameter count; VLX-Seek, a 3B-level model, matches or even exceeds the performance of larger general-purpose models on tasks like object detection.

Om AI is an artificial intelligence company based in Hangzhou. Its founder and CEO, Zhao Tiancheng, holds a Ph.D. in Computer Science from CMU and is a recipient of the Wu Wenjun Artificial Intelligence Science and Technology Progress Award. Team members come from institutions such as CMU, Tsinghua University, Zhejiang University, Microsoft, and Alibaba Cloud, and have published over 50 top-tier conference papers and hold over 50 invention patents. In 2022, Om AI received the first multimodal model certification from the Ministry of Industry and Information Technology. The newly released VLX is the company's latest achievement towards the goal of continuous perception, precise localization, and real-world action.

This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










