

According to InferenceX data released by SemiAnalysis on February 16, NVIDIA's Blackwell Ultra architecture has made significant progress in AI inference economics. The author Ashraf Eassa of the institution pointed out that compared to the previous Hopper platform, NVIDIA's GB300 NVL72 system achieves up to a 50x improvement in throughput per megawatt and reduces cost per token by up to 35x. These improvements primarily target low-latency and long-context workloads, such as AI coding agents and interactive assistants. OpenRouter's "State of Inference Report" shows that such workloads currently account for about half of AI software programming queries, a significant increase from 11% last year.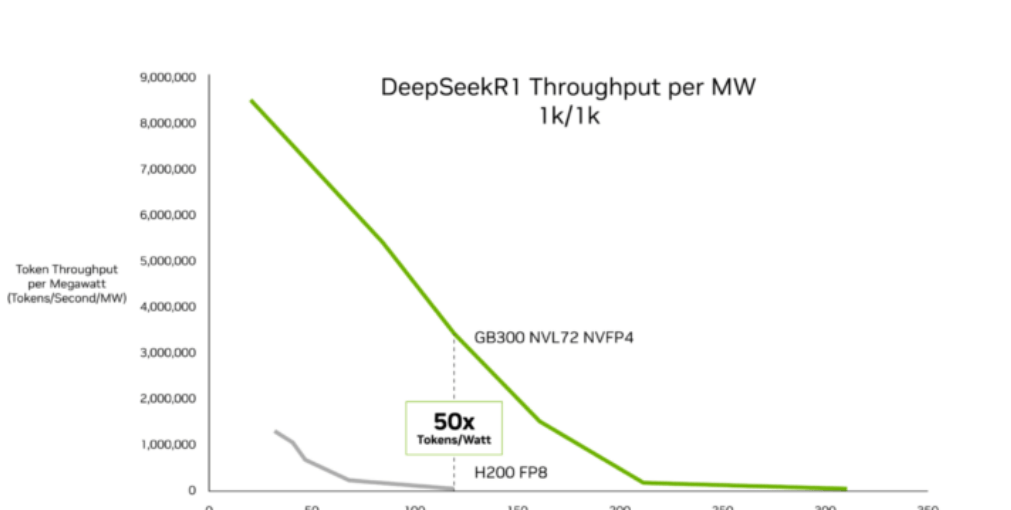
SemiAnalysis attributes the performance gains to advancements in Blackwell Ultra chip technology and continuous optimization of software stacks like TensorRT-LLM and Dynamo. The GB300 NVL72 integrates Blackwell Ultra GPUs with NVLink symmetric memory and reduces idle cycles through optimized GPU kernel design. In low-latency inference scenarios, including multi-step agent coding workflows, the GB300 NVL72 reduces cost per million tokens by up to 35x compared to Hopper. For long-context workloads, such as 128,000 token input and 8,000 token output, the GB300's cost per token is up to 1.5x lower than the GB200 NVL72, benefiting from improved NVFP4 computational performance and faster attention processing.
Cloud providers are deploying this platform at scale. Microsoft, CoreWeave, and Oracle Cloud Infrastructure are rolling out GB300 NVL72 systems for production inference of coding assistants and other agent AI applications. SemiAnalysis reports that these improvements continue the deployment momentum of Blackwell among inference providers, with early Blackwell systems reducing cost per token by up to 10x.
Chen Goldberg, Senior Vice President of Engineering at CoreWeave, stated: "As inference becomes central to AI production, long-context performance and token efficiency become critical. Grace Blackwell NVL72 directly addresses this challenge, and CoreWeave's AI Cloud is designed to translate the gains of the GB300 system into predictable performance and cost efficiency. The result is better token economics, providing more usable inference for customers running workloads at scale."
SemiAnalysis data indicates that hyperscalers are accelerating the shift towards inference-optimized infrastructure. NVIDIA's roadmap—from Hopper to Blackwell Ultra and the upcoming Rubin architecture—positions throughput per megawatt and token economics as key competitive metrics, an area of increasing focus for competitors including AMD.















