

When using large language models (LLMs), achieving high-quality output with low latency is a critical requirement, especially in real-world applications such as chatbots and AI code assistants. Currently, LLMs mostly adopt an autoregressive decoding framework, but this method is inefficient, with response time increasing linearly when generating long sequences. To improve efficiency, researchers are exploring speculative decoding within the "guess-and-verify" framework — using a smaller LLM to pre-guess text tokens, which are then verified by the original LLM to shorten response time. However, these methods often require additional training and substantial computational resources, and their acceleration effect is limited.
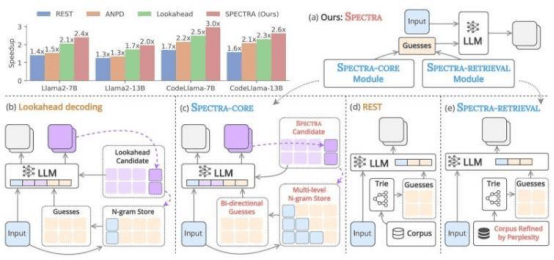
To address this issue, Professor Nguyen Le Minh and his team at the Japan Advanced Institute of Science and Technology (JAIST) have developed a new speculative decoding framework called SPECTRA. This framework can accelerate text generation without requiring additional training. "SPECTRA consists of two core components: SPECTRA-CORE, which can be seamlessly integrated into LLMs, and SPECTRA-RETRIEVAL, which further enhances performance," Professor Nguyen explained. SPECTRA-CORE uses the text distribution patterns predicted by the LLM to generate high-quality guesses. It employs bidirectional search on an N-gram dictionary to quickly and accurately predict phrases of varying lengths and continuously updates the dictionary to optimize performance.
To further increase speed, the SPECTRA-RETRIEVAL module is integrated into the system. Unlike existing methods, it filters text datasets and retains only the portions that the target LLM can easily predict, ensuring high-quality and relevant data for model training or fine-tuning, achieving seamless integration with SPECTRA-CORE. Tests on three LLM families — Llama 2, Llama 3, and CodeLlama — showed that SPECTRA achieved a 4× acceleration, surpassing non-training speculative decoding methods such as REST, ANPD, and Lookahead. Professor Nguyen stated: "By integrating the plug-and-play SPECTRA-CORE module with the improved SPECTRA-RETRIEVAL module, we can achieve significant acceleration across different tasks and model architectures while preserving the output quality of the original model."