en.Wedoany.com Reported - Renmin University of China, in collaboration with Microsoft Research, has introduced the Arbor framework, transforming autonomous optimization of AI systems from a trial-and-error process into a cumulative learning mechanism. By employing structured hypothesis management, the framework achieves a verifiable performance improvement of over 2.5 times in real-world engineering tasks.

As large language models and AI systems become more capable, autonomous optimization emerges as a core challenge. Engineering teams optimizing AI agents often need to simultaneously adjust multiple parameters such as chunking strategies, retrieval methods, and system prompts. These adjustments are intertwined, making precise attribution difficult and leading to inefficient optimization processes. Co-author Jiajie Jin noted that simply giving coding agents more time or computational resources does not yield better results. "If the goal is ambiguous or the metric is easily gameable, running longer usually just produces 'improvements' that no one actually wants, and faster."
Existing coding agents rely on conversation history as memory, but autonomous optimization tasks involve hundreds of interaction rounds, easily exceeding context window limits. Agents struggle to retain factual evidence within long histories, lose the overall structure of the research process, and tend to stagnate on early failures or chase noisy evaluation fluctuations. Meanwhile, general frameworks organize tool call chains on a shared working tree, preventing the testing of parallel hypotheses in isolated environments.
Arbor addresses this challenge through a decoupled architecture: the Coordinator acts as the principal investigator, maintaining the global state of the optimization research, proposing hypotheses, and deciding experimental directions without directly editing the codebase. The Executor is a short-lived agent that tests specific hypotheses in independent git working trees. The two components collaborate via a "hypothesis tree refinement" mechanism, representing the research process as a persistent branching tree. Each node binds a hypothesis, executable artifacts, factual evidence, and distilled insights. The Coordinator places broad ideas at the root node and specific refinements at leaf nodes, enabling simultaneous exploration of multiple competing directions. Failed experiments are recorded as negative constraints, preventing the system from repeating the same mistakes.
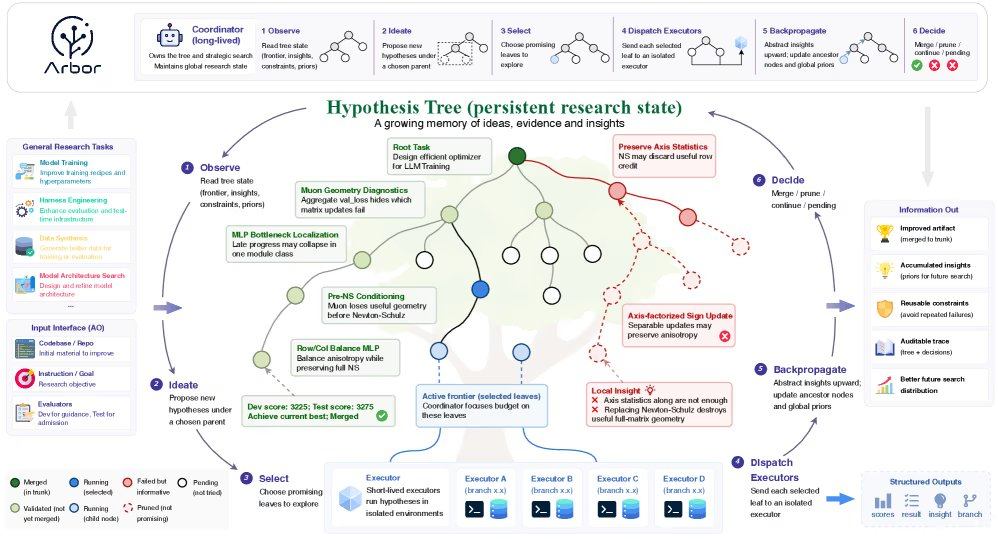
In real-world engineering scenarios, Arbor achieves clear attribute attribution by treating each optimization lever as a separate hypothesis. After the Executor returns a report, the Coordinator writes the evidence into the tree and backpropagates insights to the parent node. To prevent overfitting, the framework enforces a "merge gate," testing candidate solutions in independent working trees and merging them into the current best trunk only if they improve the held-out test score.
Researchers evaluated Arbor on an autonomous optimization task suite based on real research environments and the MLE-Bench Lite machine learning engineering benchmark. The AO suite covers tasks such as model training, framework engineering, and data synthesis. When using backbone models like Claude Opus 4.6, GPT-5.5, and Gemini-3-Flash, Arbor achieves an average relative gain over 2.5 times that of Codex and Claude Code. In the BrowseComp task for optimizing search agents, Arbor improved the system's held-out accuracy from 45.33% to 67.67%, while Codex and Claude Code plateaued at 50% and 53.33%, respectively. On MLE-Bench Lite, Arbor achieved the strongest results when equipped with GPT-5.5.
Arbor demonstrates resilience to overfitting. In Terminal-Bench 2.0 experiments, Claude Code achieved a development score of 75 but dropped to 71 on held-out data; Arbor had a lower development score of 72.22 but achieved the highest held-out score of 77.36. Cross-task transfer experiments showed that optimizing the codebase for the BrowseComp search framework significantly improved performance on unrelated tasks like HLE and DeepSearchQA.
The framework is designed to build upon existing Git workflows. Jin stated that Arbor outputs ordinary git branches, allowing existing code review and human review to inspect them directly. The primary deployment costs are the token consumption from maintaining the Coordinator and managing the tree, as well as the computational and disk resource requirements for multiple isolated working trees. The framework is suitable for tasks with clear, trustworthy metrics, tolerance for long time spans, and multiple reasonable search directions, such as pipeline optimization, data synthesis quality, and model training tuning. It should not be applied to real-time latency tasks, simple fixes, or scenarios with flawed evaluation metrics. Jin believes the next evolution is to transition each node's artifact from a single scalar score to a multi-objective Pareto search carrying vectors of accuracy, latency, and cost.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com