en.Wedoany.com Reported - NVIDIA's inference software stack on its Blackwell platform has reduced the cost per token of the DeepSeek V4 model by up to five times within a month. As enterprises transition from AI pilots to production-grade AI factories, infrastructure decisions have shifted from focusing on peak chip specifications to cost per token—measuring how many useful tokens are produced per dollar and per watt of energy while meeting latency targets. NVIDIA's inference software stack, co-designed with NVIDIA GPUs, CPUs, networking, and systems, and enhanced through a broad open-source ecosystem, continuously improves hardware performance.
Leading companies and inference providers are already experiencing the compounding value of the NVIDIA inference software stack on Blackwell. Baseten uses the NVIDIA TensorRT-LLM open-source library to serve DeepSeek V4 Pro on Blackwell GPUs for inference, coding, and long-context workloads, achieving up to a 50% increase in token output per second through proprietary runtime optimizations. Cognition leverages the NVIDIA Dynamo inference framework to manage inference GPUs, providing its team with a ready-made path to scale reinforcement learning workloads without building infrastructure from scratch. Deep Infra uses the NVIDIA inference software stack to run cutting-edge open-source models, including DeepSeek V4, at high performance on Blackwell from day one. Together AI employs NVIDIA TensorRT-LLM on Blackwell to help Cursor accelerate the path from model optimization to production endpoints, supporting its real-time coding experience.
Traditional web, search, and software-as-a-service workloads are relatively predictable, but agentic AI is different. Agents can reason, plan, invoke tools, launch specialized sub-agents, and manage large contexts across multi-turn workflows, transforming a single request into a distributed computing problem that may involve hundreds of sub-agents, thousands of tasks, and multiple large language models running on GPUs, CPUs, DPUs, and storage systems. The software stack determines whether this complexity translates into wasted compute power or lower cost per token.
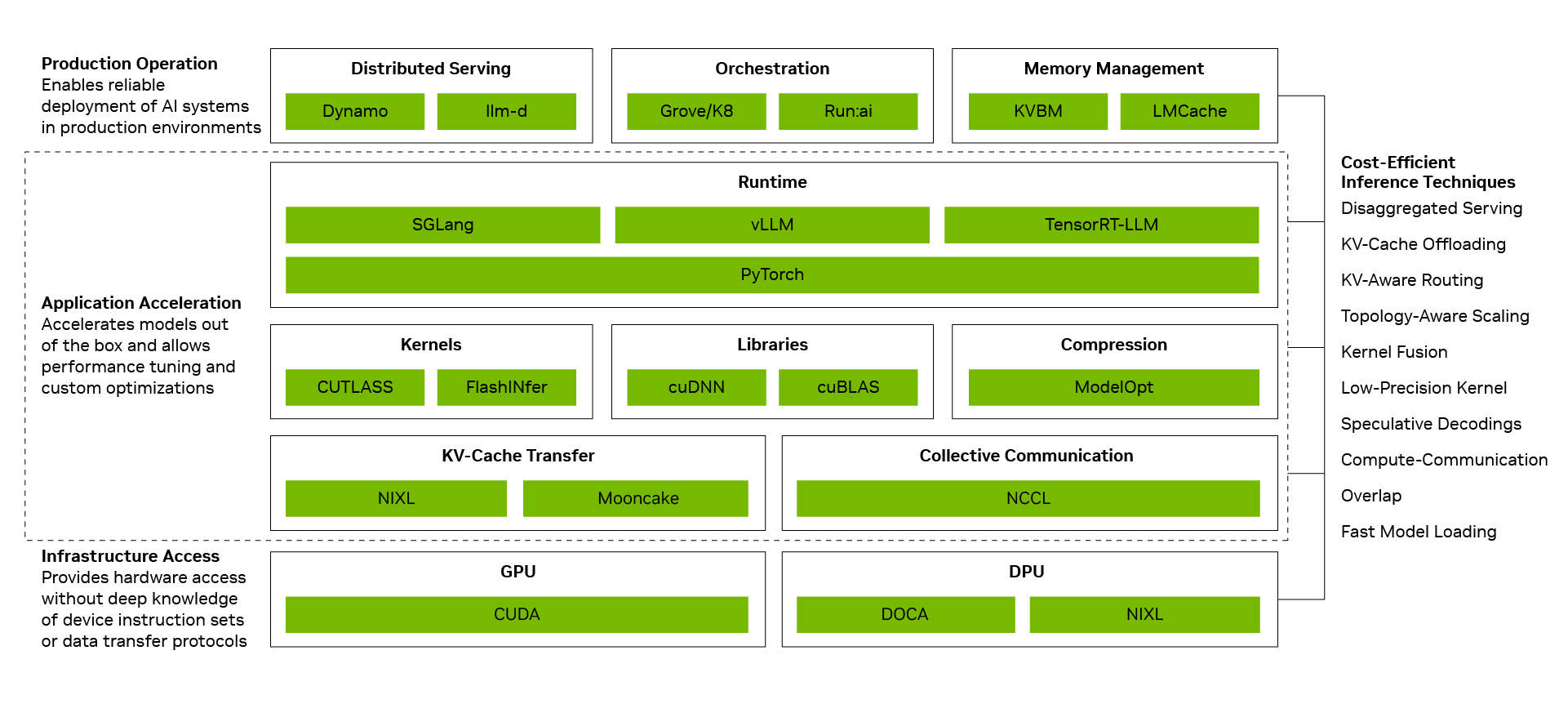
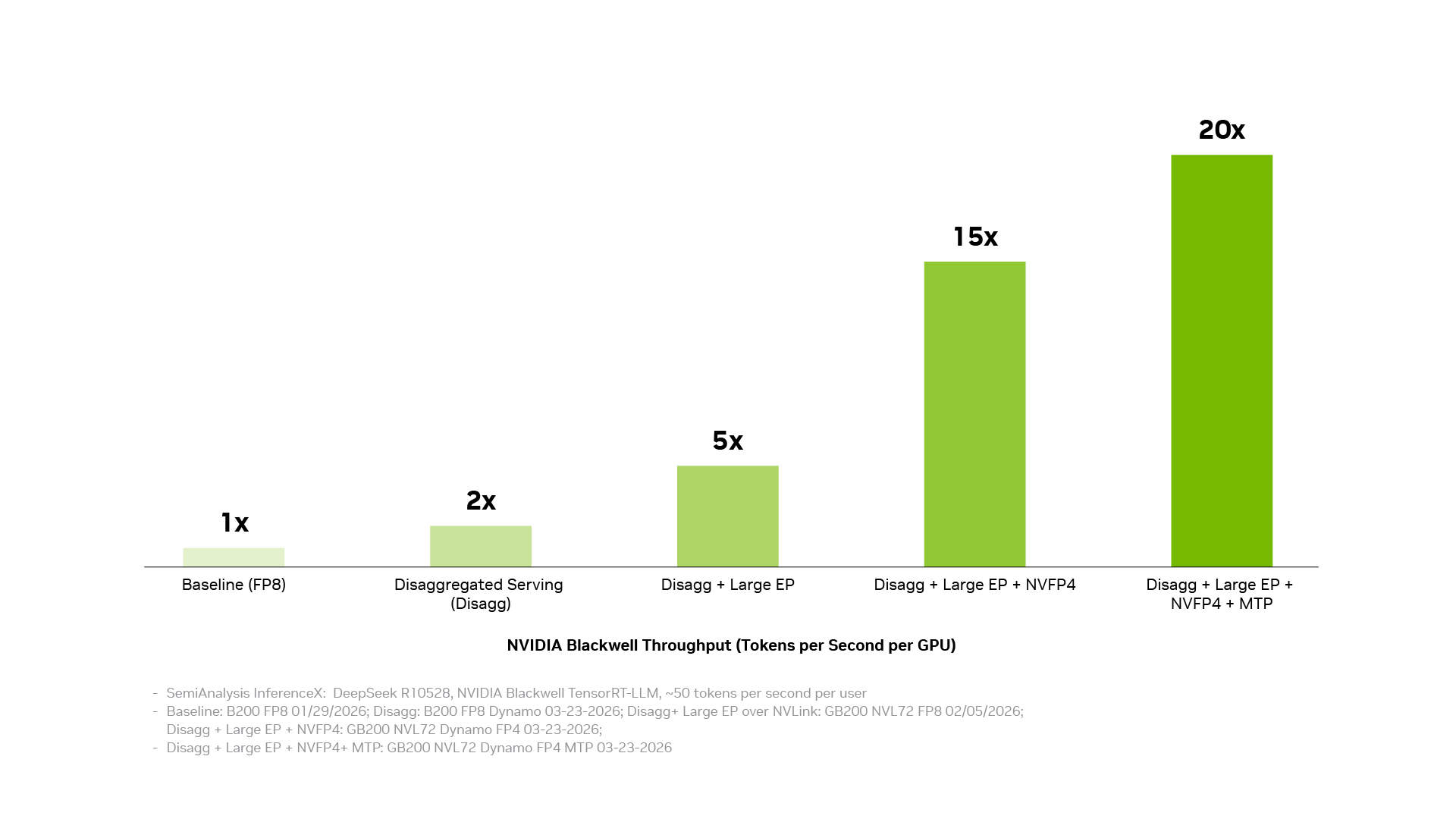
Lower cost per token comes from turning individual optimizations into system-level performance. The NVIDIA inference software stack achieves this by connecting three layers: the production operations layer coordinates distributed services, orchestration, auto-scaling, and memory management; the application acceleration layer runs models at high performance and provides developers with room for tuning and customization; and the infrastructure access layer exposes NVIDIA GPU, networking, memory, and system capabilities. When these layers work together as a system, individual optimizations compound. Decoupled services, large-scale expert parallelism based on NVIDIA NVLink interconnect technology, NVFP4 precision, and multi-token prediction each deliver significant gains, and combining them can boost throughput by up to 20 times.
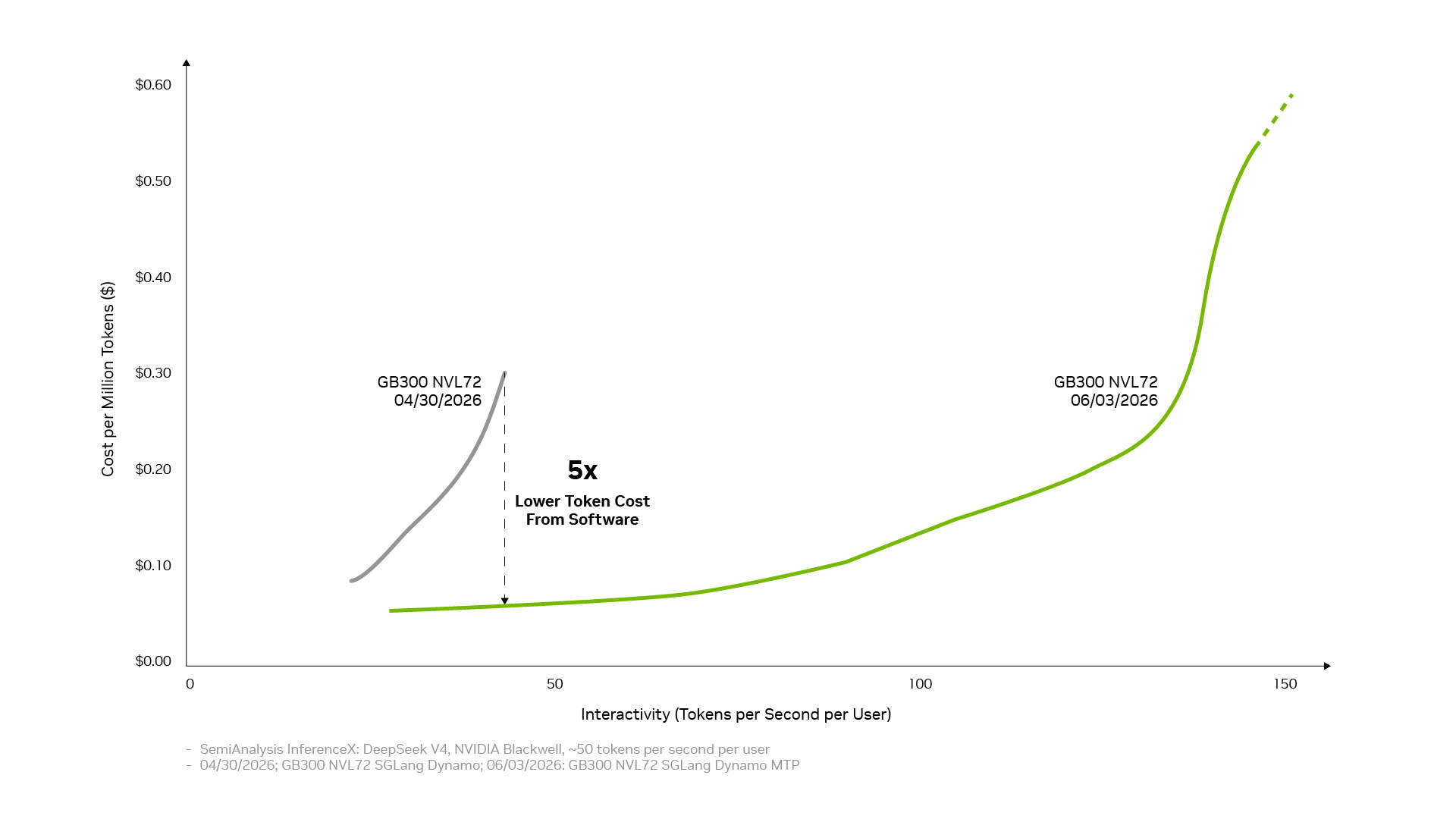
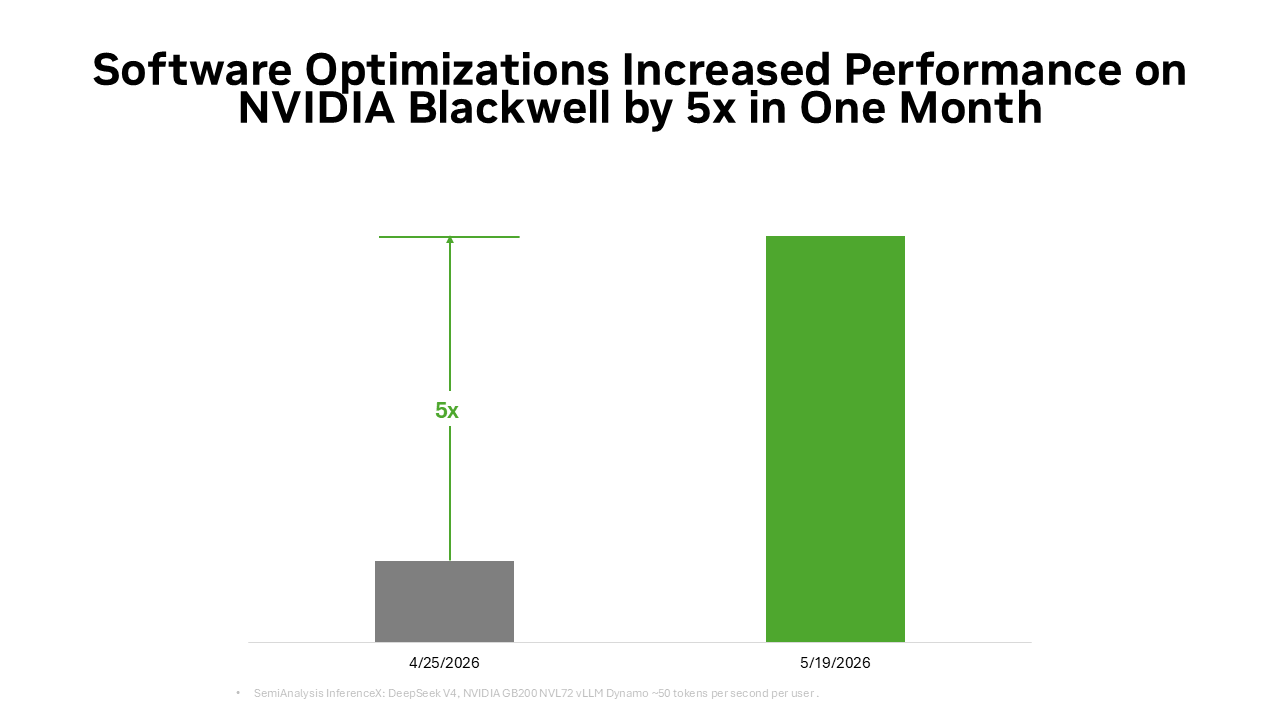
The same full-stack foundation is also amplified through the open-source ecosystem. Many widely used open-source AI frameworks and inference projects today are natively built on NVIDIA CUDA. PyTorch is a prime example, launched in 2016 with native CUDA support and co-evolving with NVIDIA architectures. When breakthrough technologies like DFlash speculative decoding or FastVideo land on PyTorch, they can run immediately on NVIDIA. When cutting-edge open models like DeepSeek V4 are released, leading inference frameworks such as vLLM and SGLang can provide deployment solutions for the NVIDIA Blackwell architecture on day one. This is why DeepSeek V4's performance on Blackwell has improved by up to five times within a month through the vLLM and SGLang frameworks, reducing the cost per token to approximately one-fifth of its original level.
This is the open-source flywheel: more developers optimize CUDA-based inference paths, more production deployments feed back into the ecosystem, and each software improvement increases token output while reducing cost per token.