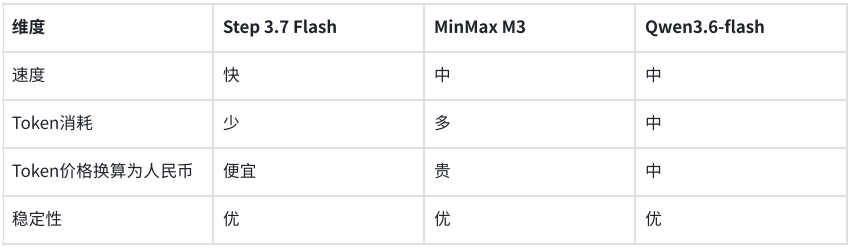
en.Wedoany.com Reported - As multimodal models transition from demonstrations to production deployment, three models—Step 3.7 Flash, Qwen3.6-flash, and MiniMax M3—have undergone real-world testing in development and business scenarios. A comparative evaluation focusing on flowchart recognition and invoice parsing shows that all three models deliver stable performance in visual understanding and structured output, though they differ in response speed and token consumption.
The evaluation, centered on quality, speed, and cost, selected two industrial scenarios: first, reconstructing business logic from system flowcharts during Agent development, and second, extracting structured information from invoices via API calls in business systems. Tests indicate that none of the three models exhibited severe misrecognition in either task, with high output usability.
In the flowchart understanding scenario, the models were required to accurately extract the business logic of 10 steps from a WeChat Mini Program login authentication flowchart. Step 3.7 Flash fully identified all 10 steps, with each step's logic perfectly matching the original flowchart. MiniMax M3 also output 10 steps with correct logic. Qwen3.6-flash merged steps 3 and 4, outputting 9 steps, but the overall logic remained correct. Given comparable output quality, Step 3.7 Flash demonstrated the fastest response speed and the lowest token consumption.
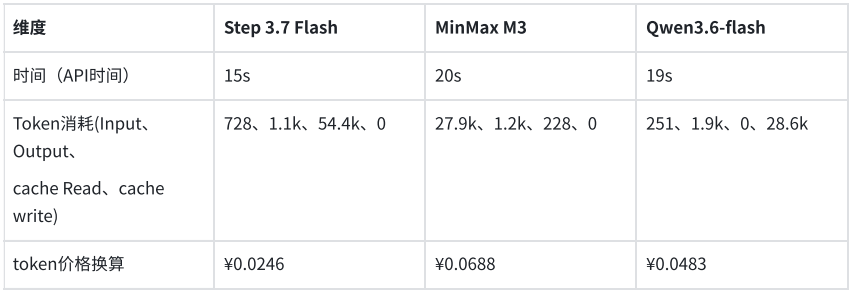
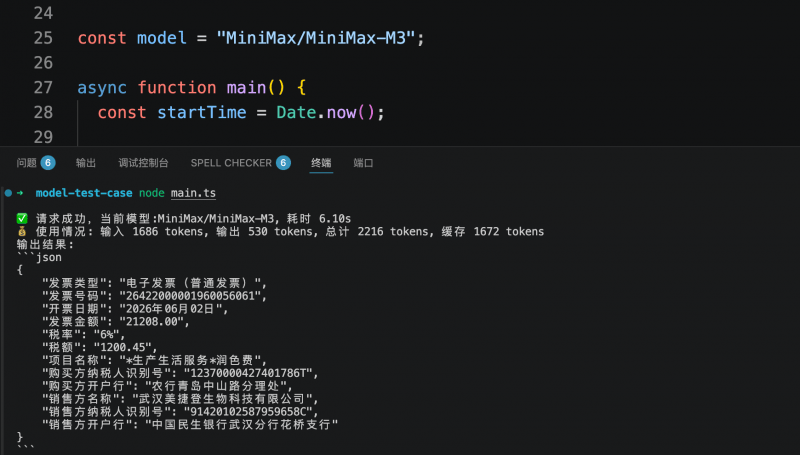
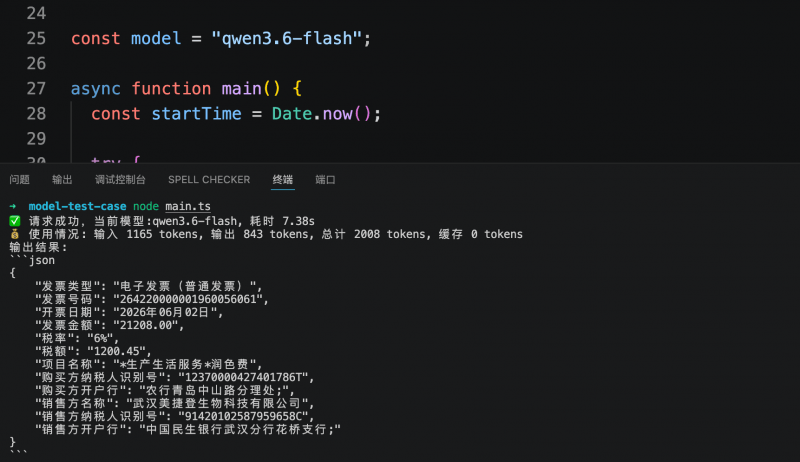
In another test targeting business systems, the models were tasked with outputting key fields from an electronic invoice according to a predefined JSON structure. All three models accurately recognized and structured the required information. Step 3.7 Flash completed the task in 5.6 seconds, consuming 1,409 tokens; MiniMax M3 took 6.1 seconds, consuming 2,216 tokens; Qwen3.6-flash took 7.38 seconds, consuming 2,008 tokens. The cost for structured extraction of a single invoice was less than 1 cent.
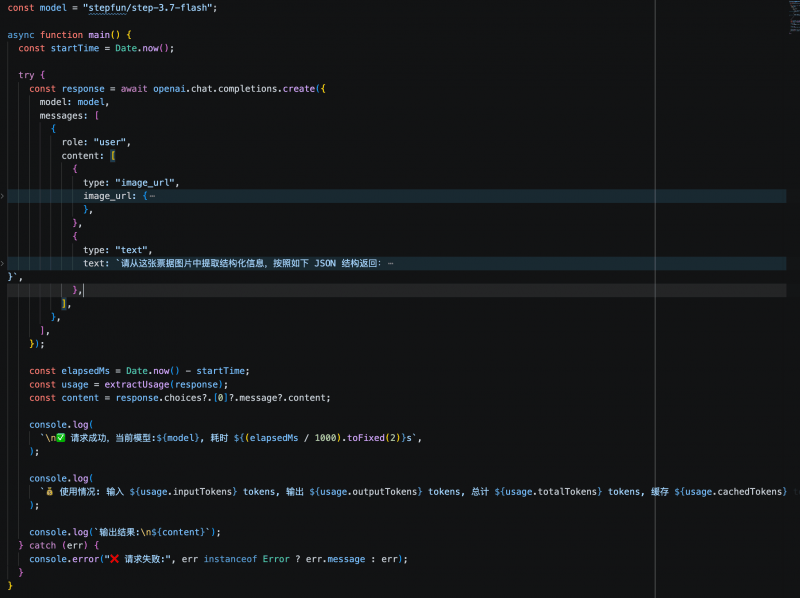

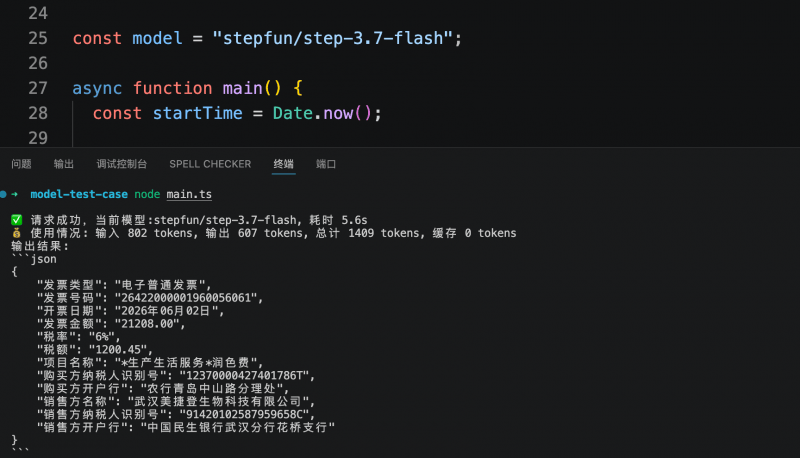
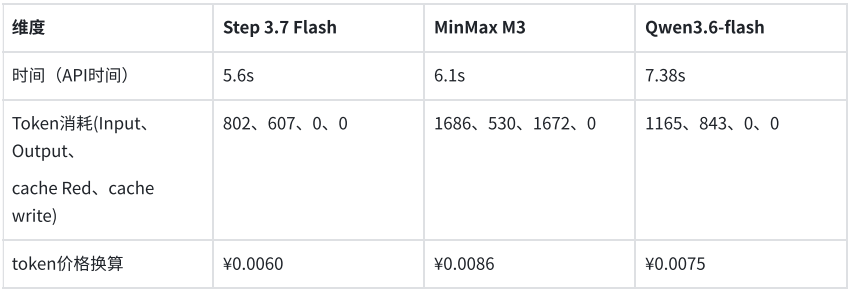
Combining both tests, the quality stability of the three models in visual understanding and structured output meets preliminary production requirements, with no extraction errors observed. For high-frequency Agent or business API scenarios, response latency and token consumption become key differentiators. In this comparison, Step 3.7 Flash, while maintaining equivalent output quality, offers faster response speed and lower cost, making it more suitable for priority deployment in production environments for testing.