en.Wedoany.com Reported - AMD has launched the Instinct MI350P for server environments. The card is compatible with standard PCIe 5.0 slots and is designed with agentic artificial intelligence as its core objective—that is, AI agents capable of proactively assisting users in completing tasks. The product is a dual-slot form factor approximately 26.7 cm in length, relying on strong airflow within rack servers for passive cooling. Its 144 GB of HBM3e stacked memory ensures it can handle AI models with 200 billion to 250 billion parameters. In comparison, the Radeon AI Pro 9700 workstation graphics card, equipped with only 32 GB of memory, hits a bottleneck around the 40 billion to 50 billion parameter range.
The GPU architecture of the MI350P shares the same origin as the Instinct MI350X/355X, which adopt an open accelerator module form factor, but its configuration is halved. The card activates only 128 compute units, whereas the OAM version features 256 CUs; the high-speed HBM3e memory is also reduced from 288 GB to 144 GB. While not officially confirmed in writing, product images show it carries only one I/O chip and four compute chips, effectively splitting the larger version's GPU package in half.
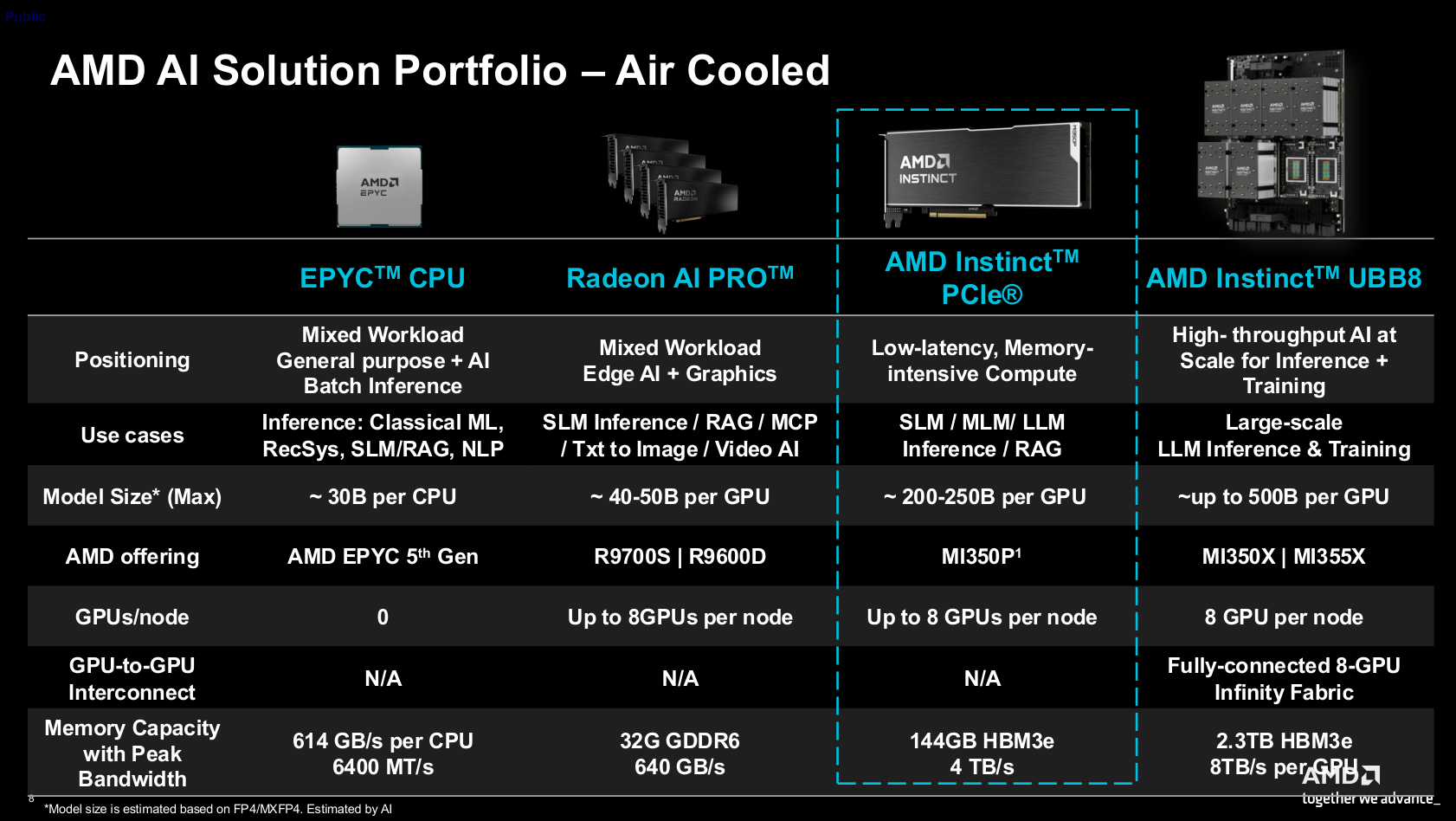
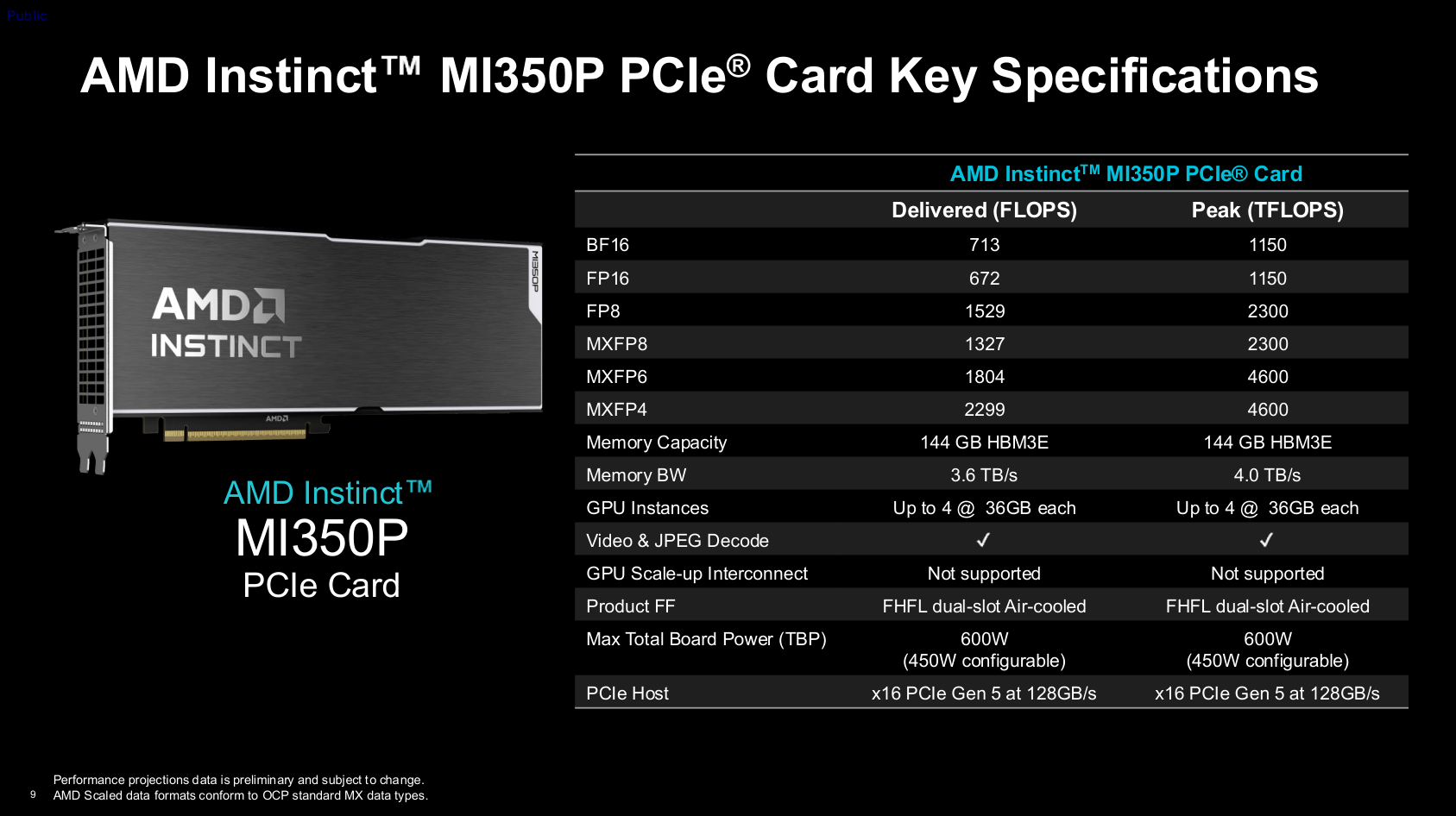
In terms of power consumption, the nominal thermal design power is 600 watts, placing it in a similar range to the Nvidia RTX Pro 6000 Blackwell or H200 NVL, and it uses a 12V-2×6 power connector, with a switchable 450-watt mode also available. To support multi-user concurrency, the card offers three partitioning modes: SPX, DPX, and CPX. SPX is full-speed mode; DPX evenly divides compute units, memory, and video/JPEG engine resources between two users; CPX splits resources into four, where two partitions share one video engine and one set of ten-core JPEG engines. The entire chip can simultaneously process 99 streams of 1080p30 AV1 video, or encode and decode 4,425 1080p JPEG images per second.
Regarding theoretical peak performance, FP8 precision can reach 2,300 Teraflops (dense matrix), roughly doubling with sparsity; both MXFP4 and MXFP6 achieve 4,600 Tflops. This level is slightly less than half that of the MI355X, while the Nvidia H200 NVL's dense matrix metric is approximately 1,670 Tflops. In actual throughput evaluation, the MI350P typically achieves 60% to 70% of its maximum rate, except for MXFP6, which only realizes 40% of its theoretical value, failing to double the ratio compared to FP8.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com