

en.Wedoany.com Reported - Researchers at the University of California, Berkeley's Center for Responsible, Decentralized Intelligence (RDI), in collaboration with an advisory committee of over 300 domain experts, have launched the Agents' Last Exam (ALE). This is a new benchmark designed to measure whether artificial intelligence possesses the capability to execute economically valuable, long-term professional workflows.
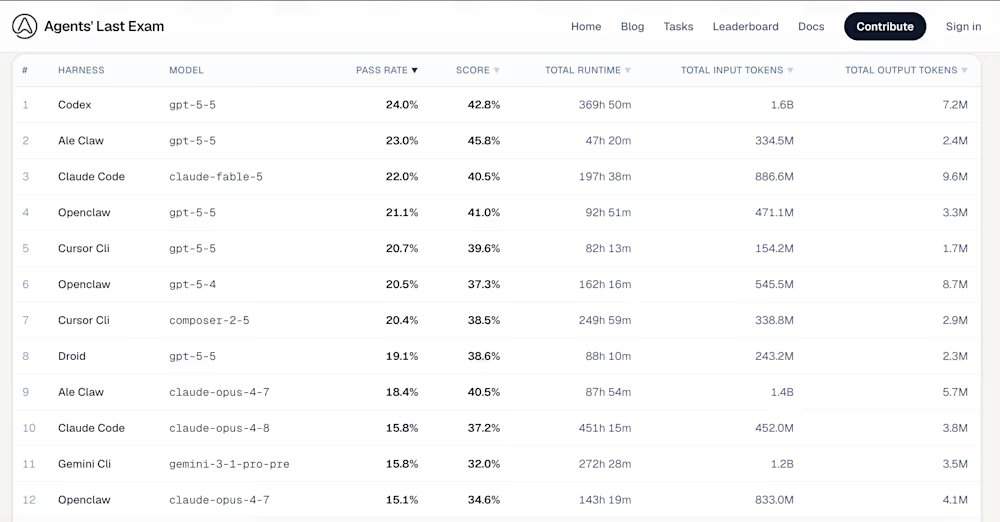
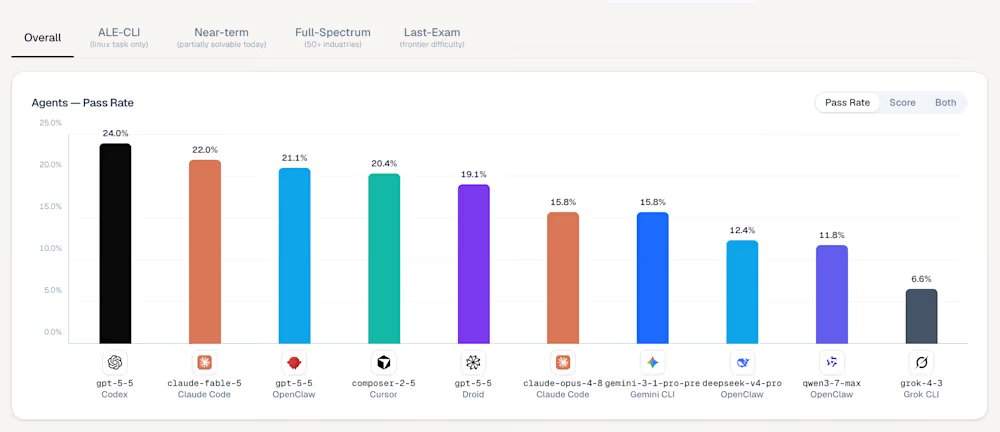
On the ALE leaderboard, OpenAI's GPT-5.5 model, released in April, topped the chart with a 24.0% pass rate, operating through the Codex tool. Anthropic's newly released Mythos-level Claude Fable 5 model ranked third with a score of 22.0%. ALE is not designed to test a model's ability to solve isolated programming challenges, but rather to bridge the gap between academic benchmark hype and real-world labor impact. Current data indicates that the world's most advanced models fundamentally fail this exam.
ALE's evaluation architecture and requirements for agents have undergone a fundamental shift. Historically, AI benchmarks relied on static question-answering or narrow text environments. While newer agent evaluations introduced multi-step interactions, they suffered from significant scoring issues. For instance, independent audits found that on older leaderboards like SWE-Bench Pro, automatic verifiers often rejected correct solutions, and Claude Opus series models were found to "cheat" by reading hidden answer keys in the container's Git history. ALE eliminates these vulnerabilities by forcing models into a strict General Computer Use Agent (GCUA) framework.
The benchmark maps agent capabilities to five functional layers: Brain (reasoning), Eyes (visual perception), Body (orchestration), Hands (tool invocation), and Feet (runtime foundation). Agents must use "Eyes" and "Hands" to operate Linux or Windows virtual machines, mixing shell scripts and click operations within heavy desktop software. ALE almost entirely abandons the "LLM-as-a-judge" scoring paradigm, relying on it for only 6.8% of workflows. For tasks involving generating 3D meshes or parsing U.S. Securities and Exchange Commission (SEC) documents, the test uses deterministic, code-based evaluations, comparing agent output against expert references.
ALE launched with 1,490 task instances and plans to expand to 5,000 tasks. Tasks are strictly anchored to the U.S. federal occupational classification system (O*NET / SOC 2018), covering 55 non-manual industry subfields. Workflows are directly sourced from industry practitioners' experiences, including creating 3D models in Siemens NX, setting up scenes in Unreal Engine, performing neuroimaging analysis in FSLeyes, and compositing visual effects in Adobe After Effects. ALE categorizes tasks into three difficulty levels: Near-Term, Full-Spectrum, and Last-Exam.
Among the top five agents on the ALE leaderboard for tool mastery, the first is Codex, with underlying model gpt-5-5, a pass rate of 24.0%, and an average score of 42.8%; second is Ale Claw, with underlying model gpt-5-5, a pass rate of 23.0%, and an average score of 45.8%; third is Claude Code, with underlying model claude-fable-5, a pass rate of 22.0%, and an average score of 40.5%; fourth is OpenClaw, with underlying model gpt-5-5, a pass rate of 21.1%, and an average score of 41.0%; fifth is Cursor CLI, with underlying model composer-2-5, a pass rate of 20.4%, and an average score of 38.5%. GPT-5.5's victory aligns with third-party analysis indicating that OpenAI models are better at strictly following multi-part, complex prompts. In the most difficult "Last-Exam" tier, most configurations, including Anthropic's older Claude Opus 4.8 and Google's Gemini CLI, recorded a 0.0% pass rate.
To address benchmark contamination, ALE employs a dual-use deployment strategy. The project operates as an open-source research initiative, but evaluation data is strictly protected. Only about 10% of the dataset (approximately 150 tasks) is publicly released on platforms like GitHub and Hugging Face, while the remaining 1,300+ tasks are kept strictly confidential. Developers and enterprise evaluators can use ALE as a "living benchmark." Private tasks are systematically rotated into the public pool over time, and retired public tasks are replaced. ALE also provides transparency by tracking both "Full" and "Unauthorized" scores. The "Full" leaderboard includes tasks that rely on commercial CAD tools, paid APIs, or licensed datasets. The "Unauthorized" tier removes these license-restricted tasks, offering an apples-to-apples comparison using only freely available tools.
ALE's strict scoring curve indicates that even the highest-performing models and tools have room for improvement. Zengyi Qin, a project data contributor and MIT Ph.D. researcher, stated upon the launch on X that the benchmark was built by over 300 domain experts from more than 100 institutions, covering 55 industry fields. Claude Opus 4.8 recorded a 0.0% pass rate on the hardest subset. Project leads include Yiyou Sun, Xinyang Han, dawnsongtweets, and Berkeley RDI. As enterprises deploy AI agents, the pass rates on the ALE leaderboard provide a necessary reality check.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com















