

en.Wedoany.com Reported - AudioX-Turbo, a high-speed audio large model, has been released, generating 10 seconds of audio in 0.24 seconds with 4-step inference. Developed by Noiz AI in collaboration with the Hong Kong University of Science and Technology and Tsinghua University, the model supports multimodal inputs including text, video, and images. By employing Distribution Matching Distillation and Adversarial Distillation, it compresses the traditional diffusion model's 50 to 200-step generation process into just 4 steps, reducing the number of model forward passes by approximately 25 times. On a single RTX 4090 GPU, generating 10 seconds of audio takes only 0.24 seconds, with a real-time factor of just 0.02, opening up possibilities for real-time audio interaction.
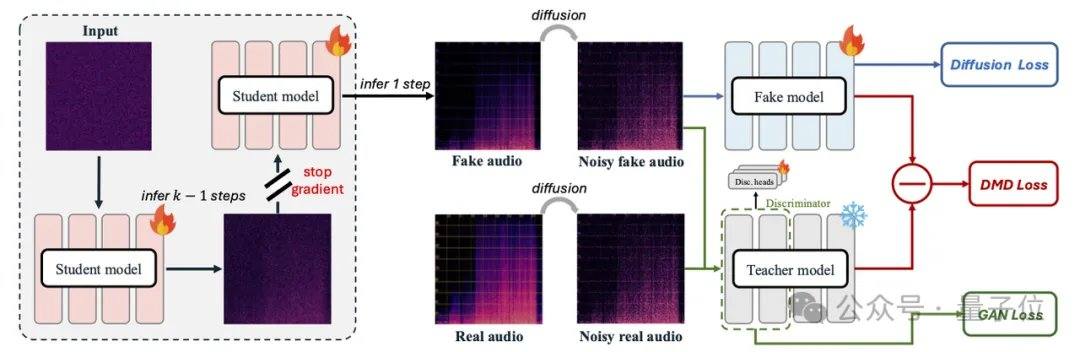
Existing mainstream audio models such as MMAudio and Stable Audio Open rely on diffusion or flow matching techniques, typically requiring tens to hundreds of iterations. AudioX-Turbo uses a native multimodal fusion Multimodal Diffusion Transformer (MMDiT) as its backbone, combined with an MAF module, and was trained from scratch with 2.7 billion parameters. Within the flow matching framework, the research team introduced Distribution Matching Distillation (DMD) and Adversarial Distillation to compress the model to 4 steps, while also removing additional NFE overhead through CFG distillation. Thanks to the diffusion discriminator, the student model surpasses the 100-step teacher model in some performance metrics.
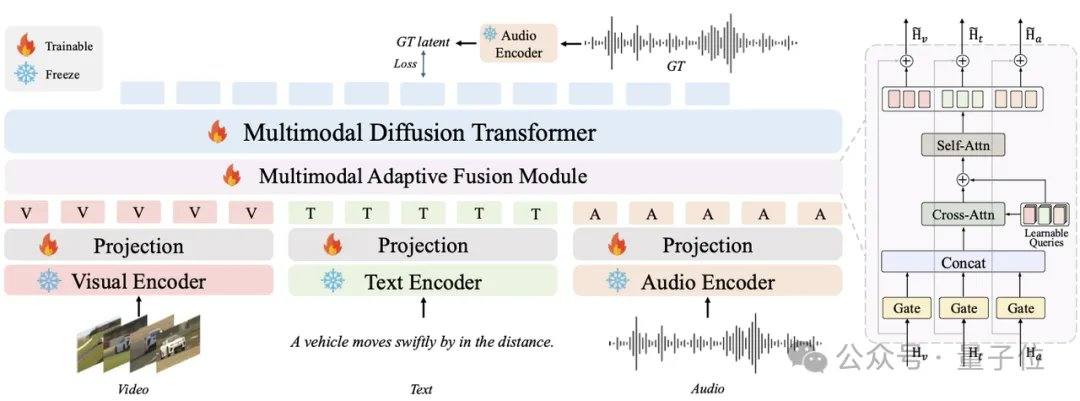
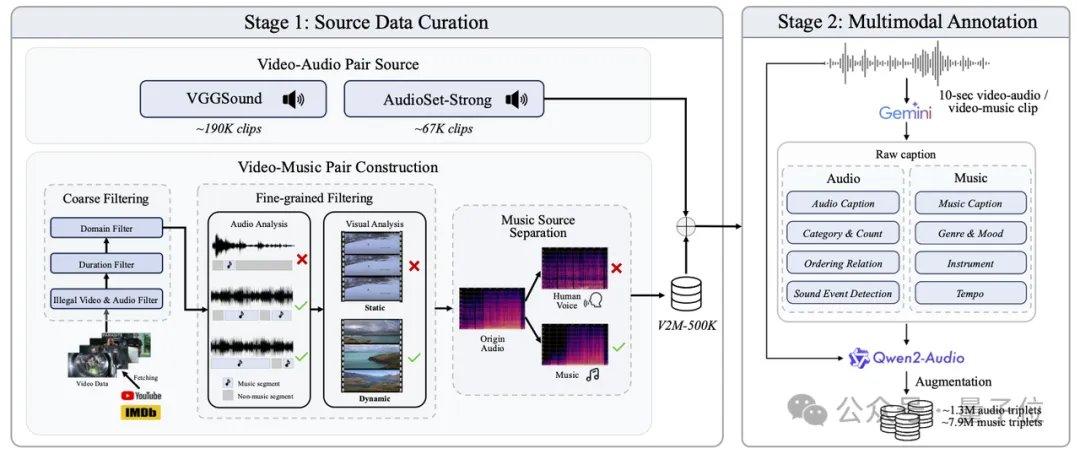
AudioX-Turbo also addresses the challenge of precise control in audio models. The research team noted that many previous models struggled with accurate timestamp control, primarily due to vague text labels in training data. To solve this, Noiz AI and the HKUST team specifically built a large-scale multimodal audio dataset, IF-caps-Pro, totaling approximately 9.2 million entries. The team adopted a "large model cascade annotation" approach, first constructing a vast number of high-quality video-audio pairs, using the Gemini 2.5 Pro model to generate structured templates with timestamps, instruments, and event counts, and then employing Qwen2-Audio for large-scale expansion, transforming the data from "vague summaries" into "scripts with precise timelines."
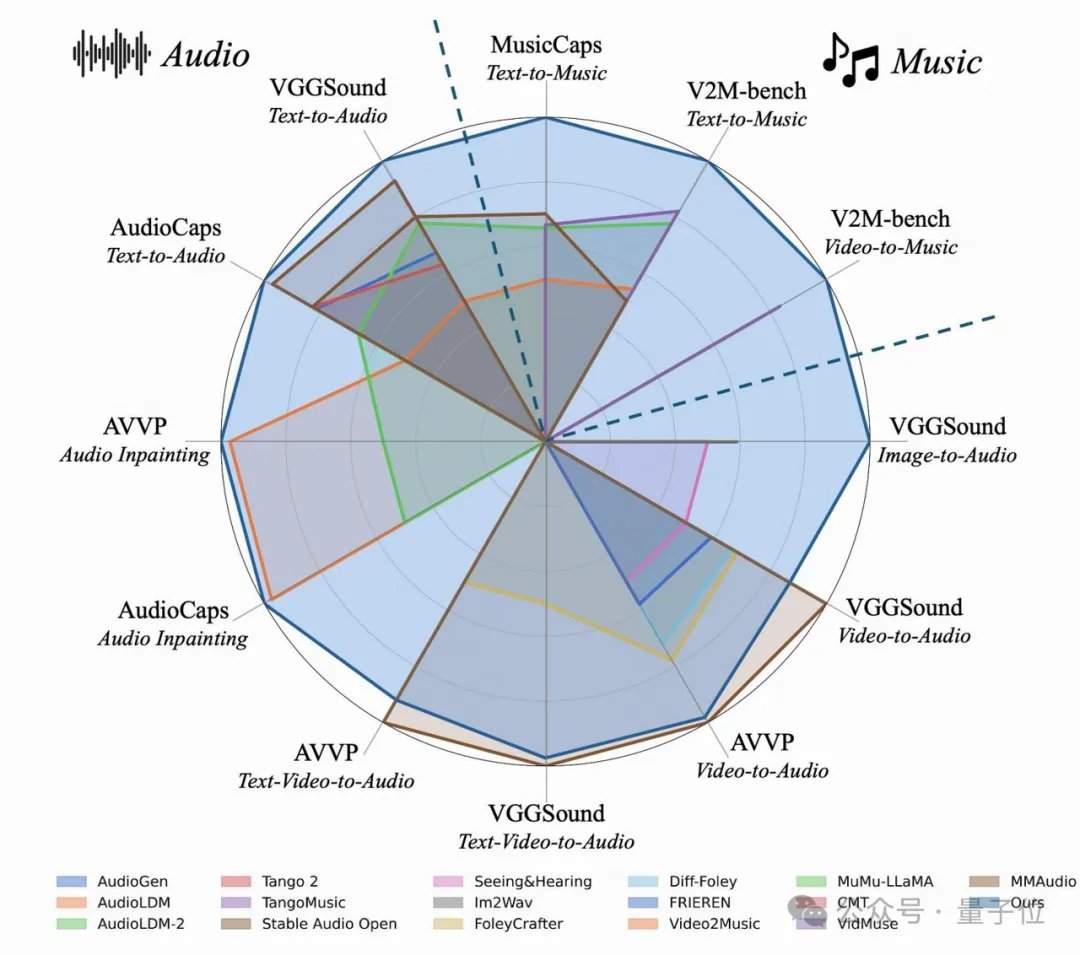
The research team unexpectedly discovered that the more detailed the text labels, the better the model's performance not only in text-to-audio generation but also in alignment when "dubbing silent videos." On classic test sets like AudioCaps and MusicCaps, the 4-step AudioX-Turbo model outperformed or matched numerous baseline models requiring 50 to 200 steps in core audio quality metrics. To evaluate instruction-following capabilities, the team constructed a dedicated benchmark, T2A-bench. In evaluations covering sound categories, quantities, timestamps, and sequential order, AudioX-Turbo demonstrated overwhelming superiority over other baseline methods, with some metrics improving by more than double.
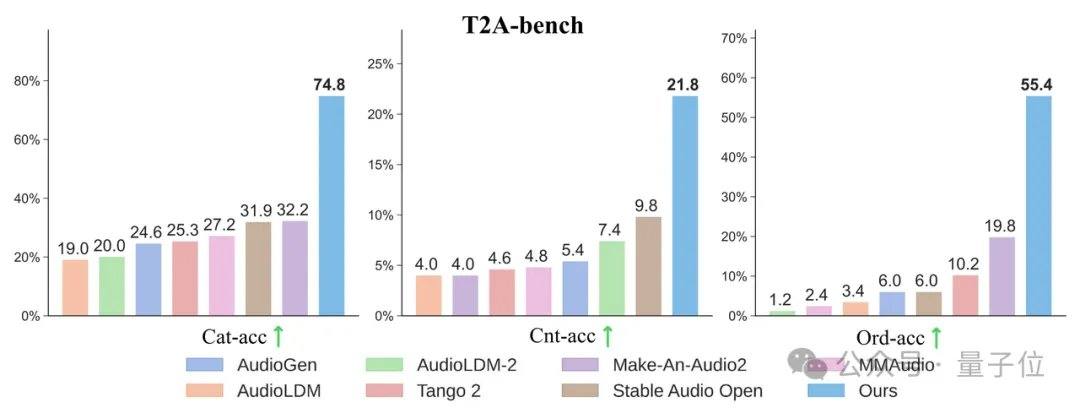
AudioX-Turbo's three key highlights include: 4-step inference, reducing computation by 25 times compared to the teacher model with better performance, and an RTF of only 0.02; a 9.2 million strong instruction dataset, achieving precise timestamp control for the first time; and support for multimodal inputs such as text, video, and images, enabling Anything-to-Audio generation. All training code and model weights for this project have been fully open-sourced. The paper, titled "AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation," is authored by teams from Noiz AI, the Hong Kong University of Science and Technology, and Tsinghua University. The project homepage is https://zeyuet.github.io/AudioX-Turbo/.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com















