en.Wedoany.com Reported - Cafe24 announced on the 23rd the launch of an AI operation infrastructure service called the "Large Language Model (LLM) Router," which integrates over 120 AI models through a single Application Programming Interface (API).
The core function of the LLM Router is to act as an "orchestrator," connecting over 120 interfaces from major AI models such as ChatGPT, Claude, and Gemini to a single platform, automatically selecting, allocating, and switching between appropriate models based on user input requests.
The service supports the use of over 120 AI models, including the OpenAI GPT series, as well as Claude, Gemini, DeepSeek, Qwen, and Llama, through a single API. Its core is the routing engine, which analyzes work types such as coding, reasoning, translation, and creation based on the user's input request content, and automatically connects to the most suitable AI model. If the user pre-specifies a range of available models, the system will automatically connect within that range, eliminating the need for users to compare or select models individually.
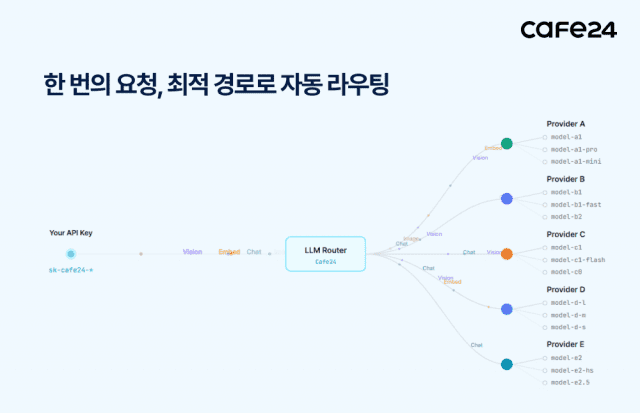
The service also offers a feature to set the priority of AI service providers based on user criteria. Among multiple AI service providers offering the same model, the system automatically connects to the most suitable provider based on user-selected criteria such as cost, speed, and processing volume. For example, for the same Claude model, if the user prioritizes cost, the system automatically connects to the most cost-efficient provider; if speed is prioritized, it connects to the fastest-responding provider. Additionally, the service supports whitelist and blacklist functions, allowing users to specify which AI service providers to allow or exclude, thereby flexibly controlling the scope of automatic connections.
To handle situations where a specific AI model is unresponsive, the LLM Router supports an "automatic failover function." Users can pre-set a primary model and alternative models; when the primary model is unresponsive, the next candidate model automatically takes over the request processing. For instance, if Claude, used as the primary model, is unresponsive, a pre-specified alternative model automatically assumes the task, thereby building a continuously operating environment.
Users can intuitively manage multiple AI models in a single environment. Through a "real-time dashboard," users can view data such as request count, cost, token usage trends, cost share per model, and success and failure ratios on a single screen. The service also supports request-level detailed logging and usage tracking by team, project, and environment, helping users more efficiently monitor AI usage and cost structures.
Users can also connect their own AI model keys to the LLM Router for use. Through the "BYOK (Bring Your Own Key)" model, users register keys for models they are currently using, such as GPT, Claude, and Gemini, and can then use those models directly within the LLM Router environment, managing the usage costs of the AI models directly.
The LLM Router adopts a credit-based usage billing model. Users receive free credits upon registration to experience the service directly.
Cafe24 plans to continue expanding support for new AI models and AI service providers in the future, and to persistently advance features that enhance the convenience of AI operation and management.
Cafe24 CEO Lee Jae-seok stated that as the variety of AI models grows rapidly, efficiently connecting and operating them has become a new challenge. He expressed the company's commitment to continuing its role as a reliable infrastructure provider, enabling users to conveniently leverage various AI models.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com