
en.Wedoany.com Reported - Robotics route debate became a focal point in the industry at the June Beijing Zhiyuan Conference. Over the past year, as the robotics sector has heated up, discussions on whether robots should follow the VLA (Vision-Language-Action) route or the World Model route have intensified. Dr. Guo Yandong, founder and CEO of ZhiPingFang, gave a clear answer in his opening speech at the conference's Embodied Industry CEO Forum: The World Model is not a competing route to VLA, but a core component within its system; after the integration of the World Model and VLA, brain-like architectures will become an important evolutionary direction for the next generation of robot brains.

This judgment is backed by ZhiPingFang's technological layout over the past three years. Guo Yandong believes that from the perspective of biological evolution, action ability does not arise in isolation; life first perceives and understands the environment before generating actions. He redefined VLA as a general term for a big data-driven end-to-end model architecture integrating multiple modalities, arguing that there is no essential difference between the World Model and VLA, nor are they substitutes. The World Model solves the problem of dense, time-dimensional 4D prediction of the physical environment, serving as part of VLA's spatial perception, helping to enhance the capabilities of the robot brain. Guo Yandong gave an example to illustrate why the two must be integrated: reasoning and cognitive logic, such as needing to pick up a tea bag before pouring water to make tea, relies on language models, while the World Model excels at short-term predictions like a cup near the edge of a table potentially falling. Merging the two enables robots to possess both short-term physical prediction and long-term task planning capabilities. ZhiPingFang also uses the World Model to generate edge data that is difficult to collect in real environments, supplementing VLA training.
Based on this judgment, in November 2025, ZhiPingFang, in collaboration with Peking University, launched the new-generation architecture Video2Act, which integrates the World Model, achieving for the first time a robot model paradigm of "predict first, execute later." Video2Act is not a traditional video generation model but a VLA architecture integrated with a 4D World Model. By modeling dense spatial information and continuously inputting action sequences, it enables robots to understand future state changes in advance and convert predictive capabilities into action decisions. In third-party evaluations, Video2Act achieved a performance improvement of over 30% compared to the most advanced similar models in Silicon Valley. In the authoritative World Model survey "World Model for Robot Learning: A Comprehensive Survey," co-authored by global top scholars including Royal Society and Royal Academy of Engineering Fellow, Turing AI world-class researcher Philip Torr, and reinforcement learning pioneer Pieter Abbeel, Video2Act was prominently cited as a representative achievement of the "World Model + VLA integration" route.

After solving the integration problem of the World Model and VLA, ZhiPingFang focused on overcoming the challenge of enabling robots to act stably and efficiently like humans. At the Zhiyuan Conference, Guo Yandong introduced ZhiPingFang's newly released brain-like embodied intelligence system, NeuroVLA. This is currently the only embodied intelligence system that simultaneously possesses three major biological motor abilities: active perception, fault self-recovery, and temporal memory. Guo Yandong pointed out that in existing VLA architectures, although robots have strong understanding capabilities, they still face issues such as slow response, motion jitter, and high energy consumption in real complex environments, because most robots rely on a single unified large model to simultaneously handle perception, reasoning, and control.
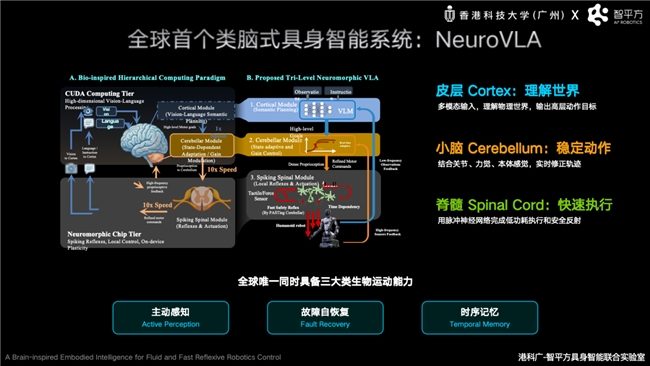
Drawing inspiration from the mechanism where the human cerebral cortex is responsible for thinking, the cerebellum for coordinating movement, and the spinal cord for instinctive reflexes, ZhiPingFang built the world's first "cortex-cerebellum-spinal cord" three-level brain-like architecture, NeuroVLA. In this architecture, the cortex handles semantic understanding and task planning, the cerebellum handles high-frequency motion coordination and dynamic correction, and the spinal cord handles millisecond-level motion execution and safety reflexes. This design enhances the stability, real-time performance, and energy efficiency of robots in the real physical world at the architectural level. Experimental results show that NeuroVLA can reduce robot motion jitter by over 75%, complete reflex responses within 20 milliseconds after a collision, and significantly reduce system power consumption.

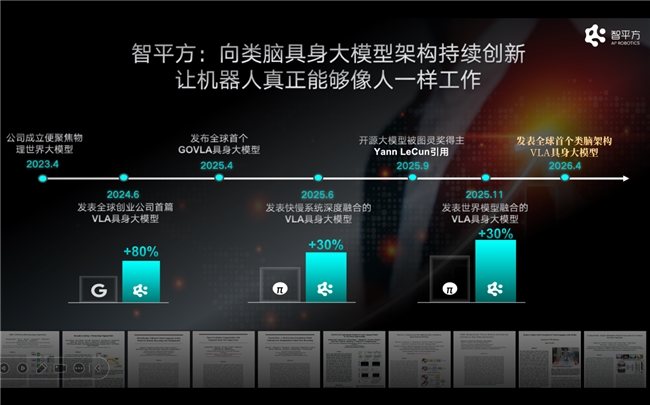
From end-to-end VLA, to Video2Act, and then to NeuroVLA, ZhiPingFang has continuously engaged in systematic innovation around the robot brain over the past three years. This evolutionary path points in the same direction: giving robots a "brain" that is more like the human brain.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com










