

A team of engineers from the University of California San Diego has recently achieved a breakthrough by developing a new method that enables large language models (LLMs) to learn new tasks with less data and computational resources. LLMs typically consist of billions of parameters that determine how they process information. Traditional fine-tuning methods require adjusting all parameters, which is costly and prone to overfitting, impairing model performance on new data.
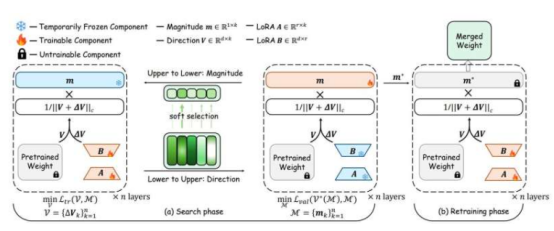
To address this issue, UC San Diego engineers proposed a smart new strategy. Instead of retraining the entire model, the method precisely updates only the most critical parts. Compared to existing fine-tuning techniques, this approach is lower in cost, more flexible, and better at generalizing learned knowledge to new scenarios.
The research team has demonstrated that, even with extremely limited training data, the method can effectively fine-tune protein language models used to predict protein properties. For example, in predicting whether peptides can cross the blood-brain barrier, the new method achieved higher accuracy than traditional approaches while reducing parameter count by 326 times. In predicting protein thermal stability, performance matched full fine-tuning with a 408-fold reduction in parameters. Professor Pengtao Xie from the Department of Electrical and Computer Engineering at the Jacobs School of Engineering, UC San Diego, stated: "With our method, small labs and startups can tailor large AI models to their needs without requiring supercomputers or massive datasets."