

Recently, researchers at the Massachusetts Institute of Technology (MIT) discovered a "positional bias" in large language models (LLMs) when processing documents or conversations, where the models tend to focus more on information at the beginning and end while ignoring the middle portions.
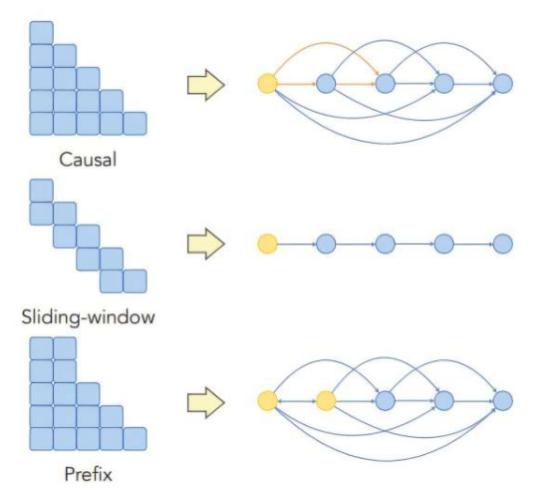
The researchers developed a theoretical framework to deeply investigate how information flows within the machine learning architecture of LLMs. They found that both the model architecture and training data can contribute to positional bias. In particular, architectural designs that affect how information propagates between input tokens within the model exacerbate this issue.
"These models are like black boxes, and users may not realize that positional bias can lead to inconsistent model behavior," said the paper's first author, Xinyi Wu. She noted that by better understanding the underlying mechanisms of the models, these limitations can be improved, leading to more reliable chatbots, medical AI systems, and code assistants.
In experiments, the researchers systematically varied the position of the correct answer within text sequences, revealing a "lost in the middle" phenomenon, where retrieval accuracy exhibited a U-shaped pattern. The model performed best at the beginning and end, with decreased performance in the midpoint.
To address this issue, the researchers proposed several strategies. They found that using different masking techniques, removing additional layers from the attention mechanism, or strategically employing positional encodings can reduce positional bias and improve model accuracy.
"By combining theory and experimentation, we can gain insights into the consequences of model design choices," said Professor Ali Jadbabaie. He emphasized that when using models in high-stakes applications, it is essential to understand when they work, when they fail, and why.
In the future, the researchers hope to further explore the impact of positional encodings and investigate how to strategically leverage positional bias in certain applications. This study not only provides a theoretical perspective on the attention mechanism at the core of Transformer models but also offers important references for improving model performance and reliability.