en.Wedoany.com Reported - Netflix has optimized query efficiency in its Apache Druid database by introducing an interval-aware caching strategy, enabling approximately 84% of analytical results to be served from cache, reducing query load by about 33%, and improving P90 query time by 66%. This optimization is primarily achieved through an external caching proxy layer, addressing redundant computations and repeated scans of large datasets caused by slightly shifting time ranges in consecutive refresh queries for rolling window dashboards.
At Netflix's scale, its real-time analytics system processes trillions of rows of data, powering dashboards for monitoring, experimentation, and operational decision-making. These dashboards frequently execute near-identical queries, such as calculating error rates or engagement metrics within sliding time windows. Evan King, co-founder of Hello Interview, noted that traditional caching treats repeated queries with slightly shifted time boundaries as different requests, leading to low cache reuse and redundant computations in Apache Druid.
Netflix's approach decomposes query results into time-aligned segments for reuse across overlapping rolling window queries. Instead of caching the complete query output, the system stores intermediate aggregations for fixed time intervals. When a new query arrives, cached segments are used for the relatively stable historical portion of the time window, with only the most recent interval's data being recomputed from Druid and merged with the cached results.
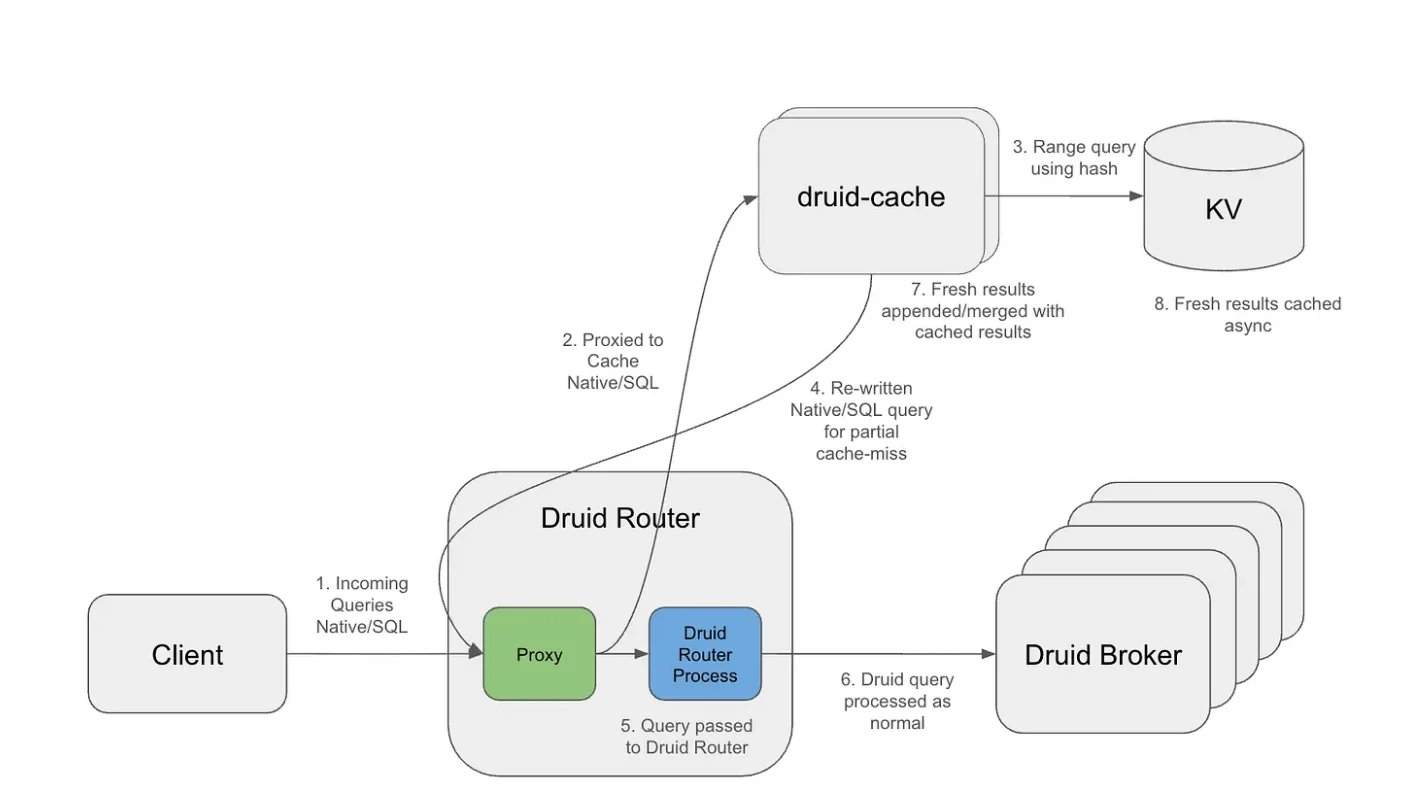
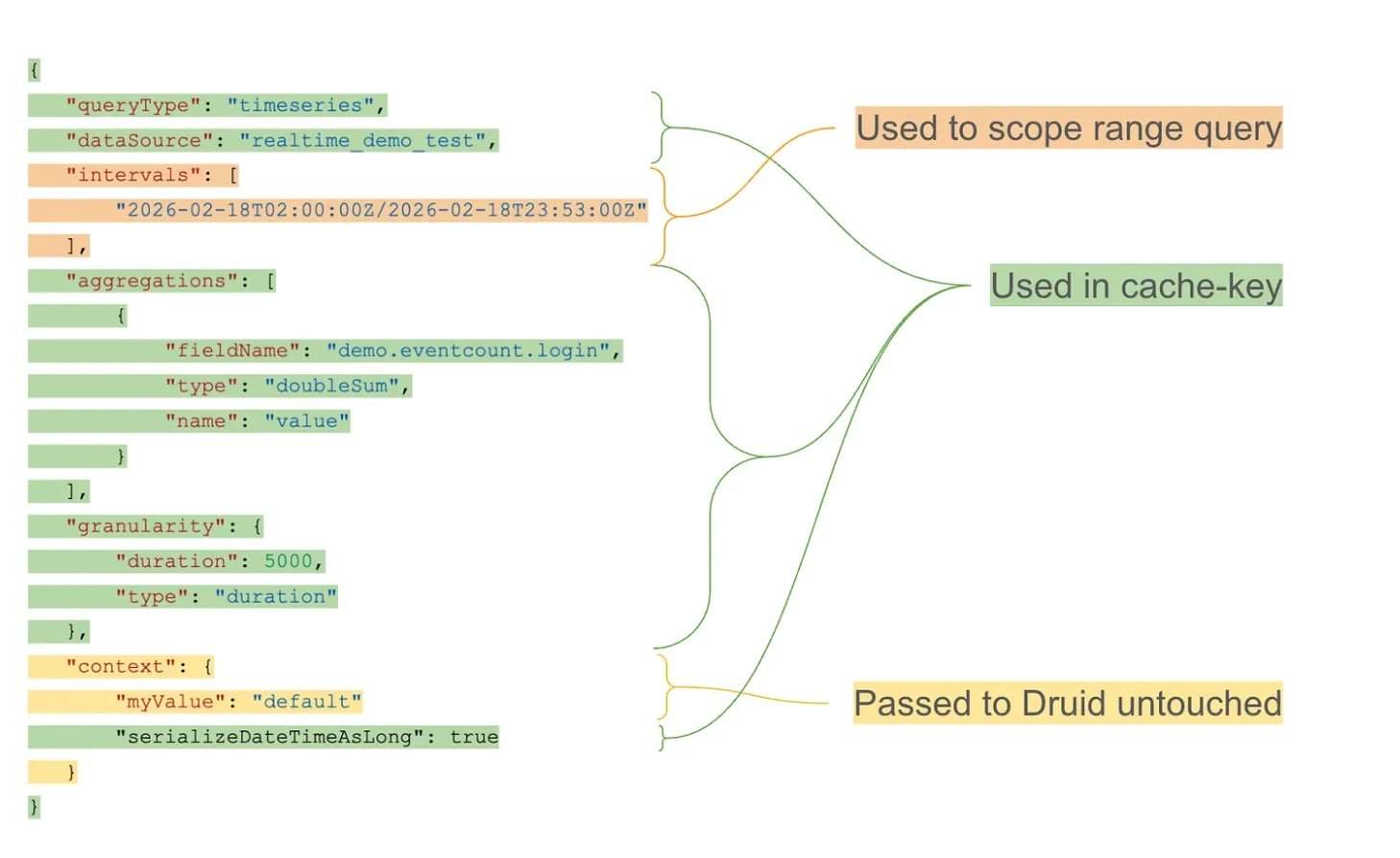
Under workloads exceeding 10 trillion rows in Apache Druid, repeated rolling window queries became a major bottleneck. The caching layer, using granularity-aligned buckets and an exponential TTL (Time-To-Live) strategy, enables long-term caching of historical intervals while maintaining the timeliness of the latest data. Architecturally, the caching layer operates as an external proxy, intercepting incoming queries, separating query structure from time intervals, and generating reusable cache keys. Cache segments are stored in a distributed key-value system, supporting independent expiration and efficient retrieval.
With this design, only the most recent interval requires recomputation, while historical segments can be reused across multiple overlapping queries. Consequently, queries reaching Druid operate over significantly reduced time ranges, scanning fewer segments and processing less data. In certain workloads, Netflix observed up to a 14x reduction in result bytes and a substantial decrease in segment scans.
The system is currently deployed as an experimental layer and continues to evolve. Future work includes extending support for templated SQL queries used by dashboard tools to reduce reliance on native Druid query expressions. Netflix is also exploring the integration of interval-aware caching directly into Apache Druid to eliminate the need for an external proxy layer and improve query planning efficiency.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com