en.Wedoany.com Reported - On June 10, 2026, Zilliz, based in Redwood City, California, announced the public preview of Zilliz Vector Lakebase, a significant update to Zilliz Cloud that combines a production-grade vector database with a shared lake-native data foundation.
Vector Lakebase is built on Zilliz Cloud's real-time vector search engine, which already serves Zillow, OpenEvidence, Exa, Filevine, MiniMax, and over 10,000 enterprises and AI teams. This update expands to three new ways of operating on the same data: interactive discovery, large-scale batch analysis, and direct search on external data lakes. The result is a single data foundation where all workloads run against a single logical copy of the data, with on-demand and batch tasks billed only when compute is active.
Charles Xie, founder and CEO of Zilliz, stated that production-grade vector search is the company's core and the reason thousands of teams choose Milvus and Zilliz Cloud. Vector Lakebase represents what Zilliz sees as the next step: a data foundation where the same vector can serve production queries, power discovery sessions, and drive PB-scale training data pipelines without copies, migrations, or parallel stacks.
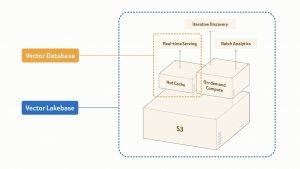
Regarding the importance of a single data foundation, AI systems are no longer a single query retrieval problem. They operate in continuous loops, including serving, learning from feedback, mining and preparing better data, and serving again. Each step typically requires separate systems for serving, exploration, and large-scale processing. Moving billions of vectors between these systems can take days. Vector Lakebase bridges this gap by building a zero-copy semantic data plane on shared lake-native storage, enabling real-time serving, interactive discovery, and batch analysis to all run against a single logical copy of data, scaling from GB to PB.
Robert Guo, Vice President of Products at Zilliz and one of the architects of Milvus, said the team wanted to find a way to keep data in one place and run vastly different workloads on it. Vector Lakebase achieves this through a unified storage layer on Vortex, tiered serving for production paths, and on-demand compute for everything else.
Vector Lakebase offers five capabilities on a single foundation. First, tiered real-time serving provides three production tiers optimized for different workloads: Performance Optimized (1000+ QPS, single-digit millisecond latency, in-memory), Capacity Optimized (100–500 QPS, sub-100ms latency, memory plus NVMe), and Tiered Storage (10–50 QPS, ~100ms latency, spanning memory, NVMe, and object storage with significantly reduced cost). All tiers default to 95–98% recall, tunable to over 99%, and are backed by Zilliz Cloud's 99.99% uptime SLA and cross-region high availability across global clusters. Second, on-demand search offers pay-per-use compute for workloads where infrastructure is idle most of the time, billing directly for object storage and compute. Zilliz's internal benchmark on 1 billion 768-dimensional vectors with 10 hours of active compute per month showed on-demand search costing $318 total, compared to $4,937 for a similar serverless path, roughly 1/15th the cost. Third, external data lake search is a zero-copy external collection mode that adds state-of-the-art indexing and full-spectrum search directly to existing Lance, Iceberg, Parquet, and Vortex tables, with incremental sync on refresh, keeping source data in place. Fourth, full-spectrum AI search supports search across vectors (dense and sparse), text, JSON, and geospatial data, enabling hybrid retrieval, BM25, regex, multi-vector and iterative search, and multi-path retrieval, with results re-rankable using Cohere, Voyage AI, RRF, and weighted, boosted, or decayed strategies. Fifth, unified lake-native storage builds on Vortex for shared storage between serving and analytics, an open columnar format designed for faster and cheaper random reads than Lance and Parquet, paired with object-store-aware indexing that reduces read amplification by over 90%. A schema backfill of 100 million rows typically completes in single-digit minutes without interrupting active query traffic.
Together, these capabilities enable AI teams to consolidate previously required parallel always-on serving clusters and separate batch systems into a single platform with consistent indexing, versioned data, and compute that can scale to zero between tasks.
Zilliz Vector Lakebase is now available in public preview on Zilliz Cloud, with serverless, dedicated, and BYOC deployment options across over 30 regions on AWS, Google Cloud, and Microsoft Azure. Register with a work email to receive $100 in free credits. Teams running serving, discovery, and analysis on separate stacks can contact the Zilliz team for customized onboarding.
Zilliz is an AI data infrastructure company and the creator of the open-source vector database Milvus, which has over 44,000 GitHub stars and more than 100 million Docker pulls. Zilliz helps enterprises and AI startups make their unstructured data searchable, analyzable, and governable. Its technology is centered on Milvus and Zilliz Cloud. Milvus is an open-source vector database built for billion-scale vector search. Zilliz Cloud extends this foundation into a fully managed Vector Lakebase platform, combining the high-throughput, low-latency serving capabilities of a vector database with the openness, scalability, and cost-efficiency of a multimodal data lake. Zilliz supports over 10,000 enterprises and AI-native startups globally, including MiniMax, OpenEvidence, Filevine, Exa, Salesforce, and Read AI. The company is headquartered in Redwood Shores, California, and is backed by investors including Aramco's Prosperity 7 Ventures, Temasek's Pavilion Capital, Hillhouse Capital, 5Y Capital, Yunchuang Capital, and Trustbridge Partners.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com