

en.Wedoany.com Reported - Microsoft recently open-sourced a new framework called SkillOpt, designed to transform AI agent skill documents into trainable objects. By introducing deep learning-style optimization methods, it systematically enhances agent performance in complex tasks.

In enterprise-level AI applications, agent skills typically exist as text-based markdown files containing instructions that guide models to adapt to specific workflows. However, traditional optimization of these skills relies on manual editing, a slow and error-prone process where users often need repeated trial and error to find instruction combinations that improve performance. SkillOpt addresses this pain point. The framework (licensed under MIT) treats skill documents as trainable objects that can be iteratively adjusted based on performance feedback, enabling document-level programmatic adaptation without altering the underlying model weights.
Yifan Yang, a senior R&D engineer at Microsoft Research Asia, noted that manual editing of skill documents faces three major failure modes: lack of step-size control leading to skill drift, absence of validation mechanisms causing seemingly correct modifications to degrade performance, and no negative feedback memory resulting in repeated errors. For example, one unrestricted rewrite reduced GPT-5.5 from 41.8 to 41.1 on the SpreadsheetBench benchmark. Yang emphasized that these errors are amplified in multi-step workflows, which is a weak point of current frontier models in zero-shot reasoning.
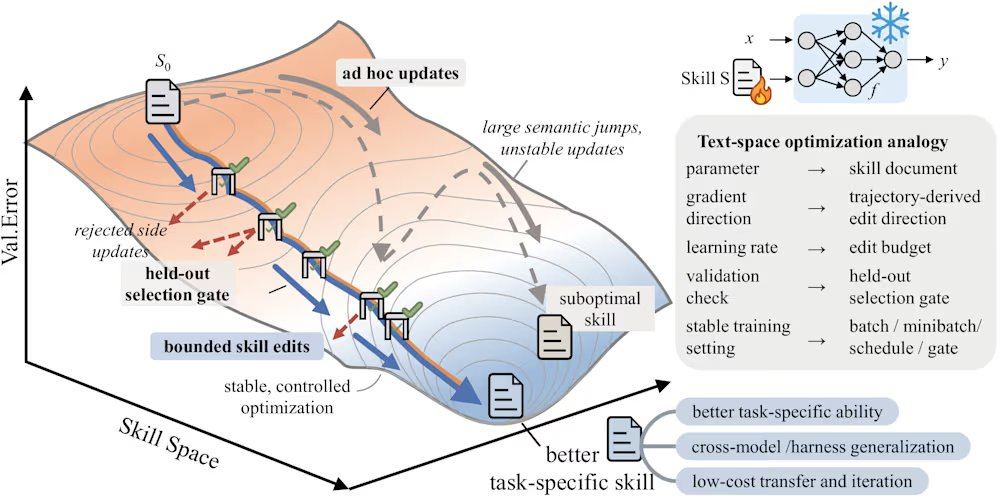
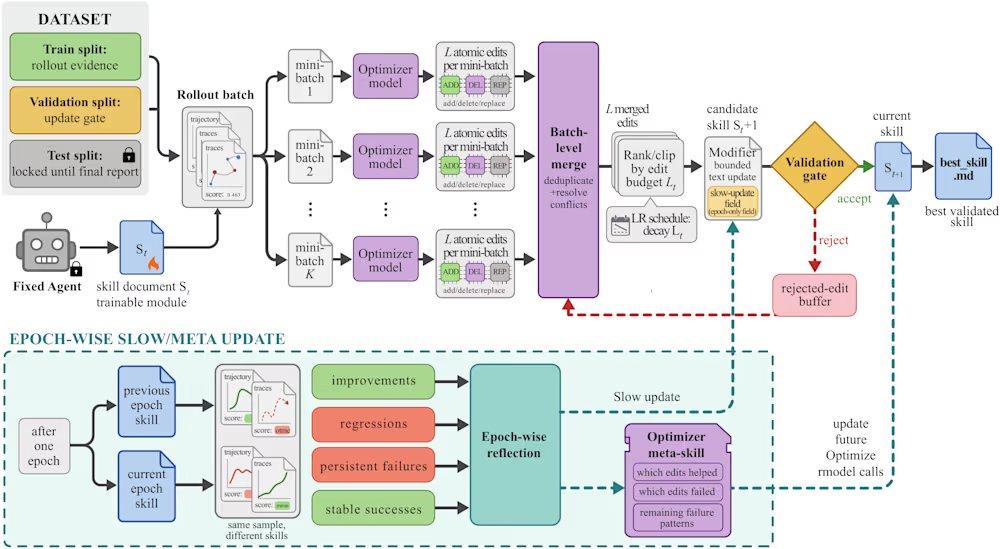
SkillOpt addresses these issues through an iterative propose-and-test loop. The process begins with a frozen target model executing a batch of tasks, generating execution trajectories as evidence of the current state. An offline optimizer then analyzes these trajectories, identifies systematic programmatic errors, and proposes structural edits to the skill document. These edits are reviewed and ranked before application, with a maximum edit budget per step (similar to a learning rate in deep learning) to prevent drastic skill version drift. Candidate skills are evaluated on a held-out validation set; if they improve the validation score, they are accepted; if they fail, they are rejected and placed into a rejection edit buffer, providing negative feedback to the optimizer. Additionally, the framework performs slow updates by comparing task performance under skills from consecutive rounds, akin to a momentum term, to convey persistent programmatic experience.
In practical evaluations, the research team tested SkillOpt on various models including GPT-5.5, GPT-5.4-mini, and Qwen3.5-4B, covering benchmarks such as single-turn question answering, multi-turn code generation, and multimodal document reasoning. Results showed that SkillOpt outperformed multiple baseline methods including TextGrad, GEPA, and EvoSkill across all 52 evaluation combinations. On the frontier model GPT-5.5, it achieved an average absolute accuracy improvement of 23.5 percentage points over the no-skill baseline. For smaller models like GPT-5.4-nano, scores nearly doubled or tripled. These performance gains directly map to critical enterprise needs, such as precise number extraction from contracts, invoices, and tables, as well as operations in AP automation, claims, and compliance. Yang stated that the improvement lies in reliability, including precise formatting, self-validation, and auditable outputs—benefits derived from learning procedures rather than memorizing answers.
The SkillOpt framework demonstrates good portability and compatibility. Experiments confirmed that the framework is execution-environment agnostic, achieving significant improvements in environments supported by tools like Codex CLI and Claude Code. For instance, a spreadsheet skill trained entirely within the Codex loop could be directly transferred to Claude Code without any changes, driving a performance improvement of up to 59.7 percentage points over the native Claude Code baseline. Additionally, skill artifacts can be transferred across model scales; skills optimized for GPT-5.4 still yielded positive gains when deployed on smaller GPT-5.4-mini and GPT-5.4-nano models. The final deployed skill documents never exceeded 2,000 tokens, with a median length of approximately 920 tokens, making them highly readable and auditable.
In terms of cost, SkillOpt imposes a light practical burden for everyday enterprise use cases. Yang mentioned that in community frameworks like GBrain, SkillOpt updates run on Claude Sonnet, with the average cost of training a skill for a single task ranging from $1 to $5, and this optimization cost is a one-time investment. However, effective operation of the framework requires two conditions: dozens of representative examples and a scoreable feedback signal. Teams should avoid applying it to open-ended or subjective tasks. Meanwhile, SkillOpt can work synergistically with existing orchestration stacks like DSPy, as they are complementary rather than substitutive. Looking ahead, the open-source community has begun deploying periodic SkillOpt runs on past agent trajectories to build a self-optimizing code agent plugin ecosystem. Yang believes that skills represent the fastest, cheapest, and most reversible first step for AI to autonomously discover knowledge and improve its own behavior, with the same mindset pointing toward agents ultimately self-optimizing all the way down to their own weights.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com















