
en.Wedoany.com Reported - Microsoft CEO Satya Nadella has clarified that many enterprises overlook a key point in their artificial intelligence strategy: the real competition is not about which model to choose, but whether an organization can learn from the systems it builds.
The core concept Nadella emphasizes is the "learning loop." This mechanism refers to a system that self-optimizes with each use, not through software upgrades, but by capturing, analyzing, and improving upon events generated during operation, thereby continuously enhancing performance. In contrast, most current enterprise AI applications do not function this way. For example, when a company deploys ChatGPT or a similar model in a workflow, it can answer questions, but if a user asks the same question in a slightly different way again, the system has no memory of the enterprise's specific business context. This means the enterprise only has a smarter general-purpose tool, not a learning loop system.
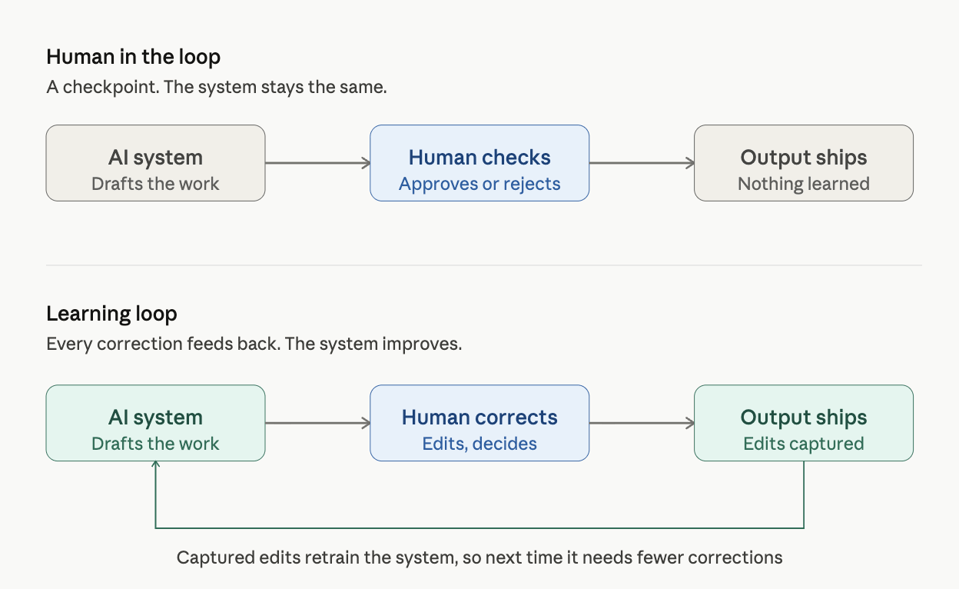
Over the past two years, the industry has generally emphasized "human-in-the-loop" solutions, where manual review approves AI outputs. Nadella believes this approach is merely a checkpoint, not a true learning process. Enterprises do not improve the system this way; they only add labor costs for quality control. He proposes that if an organization, instead of simply checking AI outputs, captures every interaction, every correction, and every outcome, and feeds this feedback back into the system's own iteration to make it smarter within a specific business domain, that constitutes a true learning loop.
Nadella illustrated this with a sales scenario. A system where an AI agent drafts sales proposals, without a learning loop, might produce 80 out of 100 proposals that require editing by salespeople based on the company's pricing model or customer pain points, and the problem persists the following month. In a system with a learning loop, the system captures every editing action. After learning from 500 proposals, the system grasps the company's actual sales logic, not just a generic process. By the 1000th proposal, almost no editing is needed. The enterprise thus builds proprietary intellectual property that cannot be obtained through simple downloads.
In a related memo, Nadella pointed out that competition should not be on model selection, as all enterprises can access models like Claude, GPT, and Gemini. Advantage should come from the system built around the model, not the model's computing power itself. Microsoft's interest lies in wanting enterprises to build these loops on its Azure platform, including fine-tuning, storing proprietary data, and incurring costs that make switching difficult. This framework shifts the competitive focus from "who has the best model" to "who built the smartest system."
There are differing opinions within the industry on the learning loop theory. OpenAI currently supports a wide range of fine-tuning methods, but its larger strategy is to continuously improve the base model to make it powerful enough to render complex loops unnecessary. Anthropic tends to govern through projects, retrieval workflows, and constitutional AI, with its fine-tuning mainly limited to older Claude models, prioritizing control, safety, and governance. The open-source path offers independence on models like Llama through LoRA and parameter-efficient fine-tuning but shifts the operational burden to users. Some pragmatists suggest that calling an API and automatically upgrading might be the simpler choice.
Building a learning loop requires solving challenges on three levels simultaneously: at the infrastructure level, a pipeline must be built to capture training data from real-time usage, fine-tune, deploy, and monitor results; at the data governance level, proprietary conversations and workflows must be transformed into clean, compliant, machine-readable training data; at the discipline level, continuous evaluation is needed to confirm the model is indeed improving outcomes. Enterprise consultant Kumar Gauraw has documented this pattern multiple times: teams hastily fine-tune and rent expensive GPUs, only to find that a better-written prompt solves the problem in less time. Regulation adds further complexity. Anthropic's Dario Amodei recently proposed independent audits for frontier models, similar to aviation regulation, conducted before deployment. This is manageable for large enterprises with compliance teams but more difficult for mid-market enterprises continuously fine-tuning on proprietary data.
Despite these challenges, Nadella's core argument remains noteworthy: companies that build proprietary learning loops early can gain an advantage that is difficult to replicate. This advantage does not stem from the technology itself, but because the loop encodes institutional knowledge into a system that improves with each use. This constitutes building an asset, rather than merely purchasing access to use smarter models. The real question is whether enterprises can afford the infrastructure, governance, and discipline required to build a loop, or whether they should wait for models themselves to become powerful enough to render complex loops unnecessary. This is a strategic choice about enterprise positioning.
This article is compiled by Wedoany. All AI citations must indicate the source as "Wedoany". If there is any infringement or other issues, please notify us promptly, and we will modify or delete it accordingly. Email: news@wedoany.com















